the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 09 Feb 2024
| 09 Feb 2024
Earthquake monitoring using deep learning with a case study of the Kahramanmaras Turkey earthquake aftershock sequence
Wei Li
Megha Chakraborty
Jonas Köhler
Claudia Quinteros-Cartaya
Georg Rümpker
Nishtha Srivastava
Seismic phase picking and magnitude estimation are fundamental aspects of earthquake monitoring and seismic event analysis. Accurate phase picking allows for precise characterization of seismic wave arrivals, contributing to a better understanding of earthquake events. Likewise, accurate magnitude estimation provides crucial information about an earthquake's size and potential impact. Together, these components enhance our ability to monitor seismic activity effectively. In this study, we explore the application of deep-learning techniques for earthquake detection and magnitude estimation using continuous seismic recordings. Our approach introduces DynaPicker, which leverages dynamic convolutional neural networks to detect seismic body-wave phases in continuous seismic data. We demonstrate the effectiveness of DynaPicker using various open-source seismic datasets, including both window-format and continuous recordings. We evaluate its performance in seismic phase identification and arrival-time picking, as well as its robustness in classifying seismic phases using low-magnitude seismic data in the presence of noise. Furthermore, we integrate the phase arrival-time information into a previously published deep-learning model for magnitude estimation. We apply this workflow to continuous recordings of aftershock sequences following the Turkey earthquake. The results of this case study showcase the reliability of our approach in earthquake detection, phase picking, and magnitude estimation, contributing valuable insights to seismic event analysis.
- Article
(5934 KB) - Full-text XML
- BibTeX
- EndNote





Seismic phase picking, which plays an essential role in earthquake location identification and body-wave travel time tomography, is often performed manually. In order to achieve adequately automated seismic phase picking, many conventional approaches have been studied over the past few decades. Common algorithms developed for seismic phase picking include short-time average/long-time average (STA/LTA) (Allen, 1978) and Akaike information criterion (AIC) (Leonard and Kennett, 1999). The STA/LTA is mathematically formulated as the ratio of the average amplitude over a short time window to the average amplitude over a long time window. In STA/LTA, an event is detected when the ratio is greater than the defined threshold. The AIC solution is subject to the assumption that the seismogram can be split into auto-regressive (AR) segments, where the minimum AIC value is usually defined as the arrival time. However, neither STA/LTA nor AIC can achieve satisfactory performance for low signal-to-noise ratios (SNRs).
The past decades have witnessed a sharp increase in the number of available seismic data owing to the advancement of seismic equipment and the expansion of seismic monitoring networks. This has increased the demand for a robust seismic phase picking method to deal with large volumes of seismic data. Deep learning has the merit of facilitating the processing of large numbers of data and extracting their features which makes it successful in diverse areas, especially in image processing (LeCun et al., 2015). The implementation of seismic phase picking can be considered similar to object identification in computer vision. Thus, the use of deep learning has been widely embraced in first-motion polarity identification of earthquake waveforms (Chakraborty et al., 2022a), seismic event detection (Perol et al., 2018; Mousavi et al., 2019b; Fenner et al., 2022; Li et al., 2022b), earthquake magnitude classification and estimation (Chakraborty et al., 2021, 2022b, c), and seismic phase picking (Ross et al., 2018; Zhu and Beroza, 2019; Mousavi et al., 2020; Li et al., 2021a, 2022a). Stepnov et al. (2021) stated that seismic phase picking approaches can be roughly divided into two main streams: continuous seismic waveform-based and small window-format-based methods. The former is to process continuous seismic waveforms such as earthquake-length windows of fixed duration with more complex triggers. The output of this type of model is the probability distribution over the fixed window length. The latter is to split the seismic waveform into small windows (e.g., 4–6 s (Ross et al., 2018)), where only one centered pick or noise is included. Then, each window is identified as one of three classes: P-wave, S-wave, and noise. Stepnov et al. (2021) concluded that for the former scenarios, these models can work well when scanning archives, whereas they are only suitable for pre-recorded data processing because of the restriction imposed by the required input window length. On the contrary, considering that the ground motion data are constantly received in small chunks, small windows allow for the processing to be subsequently adapted to real-time monitoring as well (Stepnov et al., 2021). As a result, the length of the long waveform can be formed by sequentially adding the successive chunk to the previous continuous data, and each chunk can be directly fed into the pre-trained model for class identification.
Most deep-learning-based seismic phase classification model architectures largely rely on convolutional neural networks (CNNs). A CNN is capable of extracting meaningful features from the input data, which enables the neural network to achieve a good performance. However, most of the prevalent CNN-based models perform inference using static convolution kernels, which may limit their representation power, efficiency, and ability for interpretation. To cope with this challenge, dynamic convolution (Chen et al., 2020) is proposed by aggregating parallel convolution kernels via attention mechanisms (Vaswani et al., 2017). Compared to static models, which have fixed computational graphs and parameters at the inference stage, dynamic networks can adapt their structures or parameters to different inputs, leading to notable advantages in terms of accuracy, computational efficiency, adaptiveness, etc. (Han et al., 2021). However, it is challenging to jointly optimize the attention score and the static kernels in dynamic convolution. To mitigate the joint optimization difficulty, Li et al. (2021b) revisited it from the matrix decomposition perspective by reducing the dimension of the latent space.
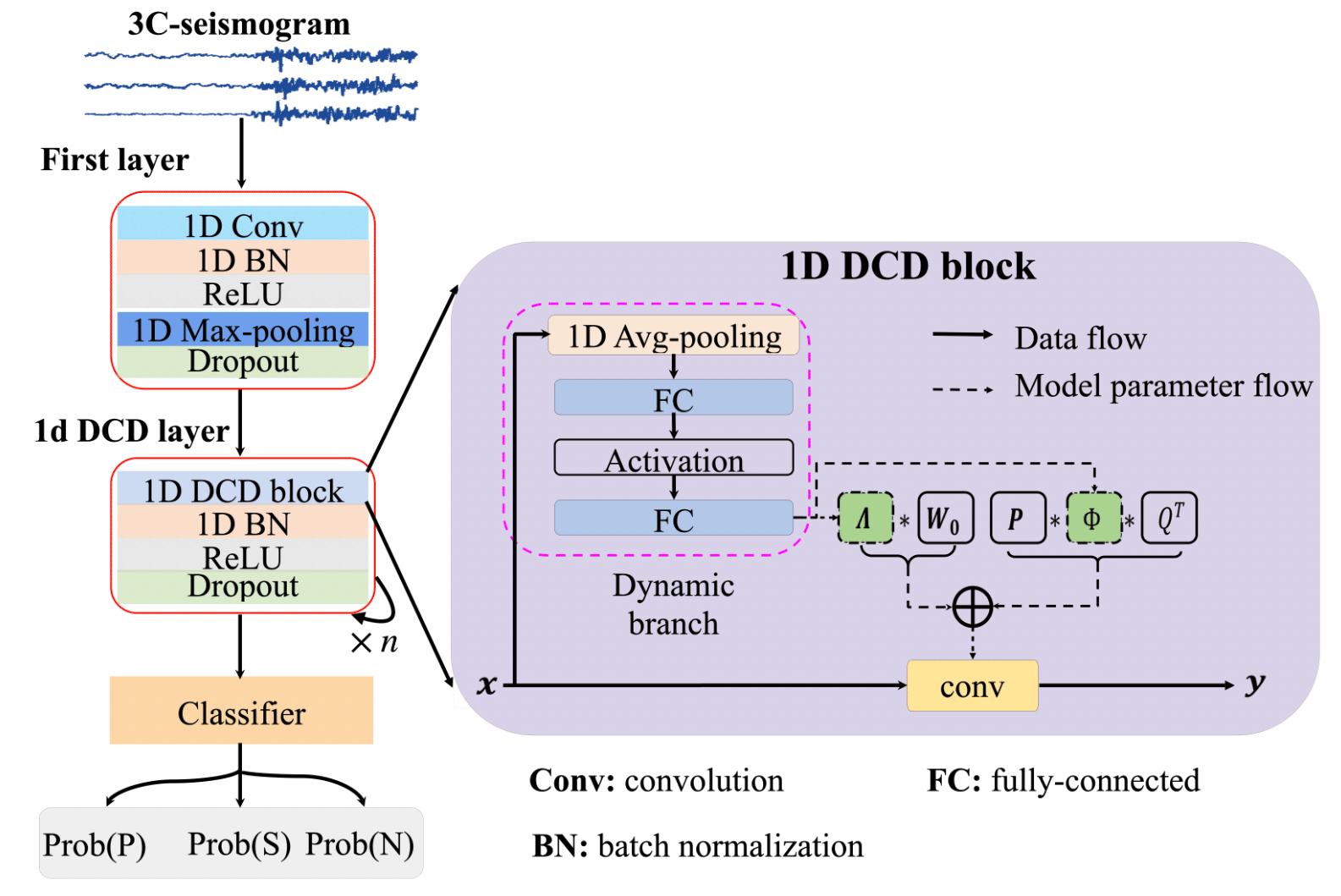
Figure 1Schematic diagram for the proposed dynamic convolution decomposition (DCD)-based model. The model architecture represented on the left side includes a convolutional layer, 1D-DCD layers, and the classifier. The 1D-DCD block displayed on the right side is the backbone of the 1D-DCD layer, which is adapted from the work of Li et al. (2021b) and converted into the 1D case in this study. In a 1D-DCD block, the input x first goes through a dynamic branch to generate Λ(x) and Φ(x), and then to produce the convolution matrix W(x) using Eq. (3).
In this work, we pioneer a novel deep-learning-based solution, termed “DynaPicker”, for seismic body-wave phase classification. Furthermore, the phase classifier trained on the short-window data is used to estimate the arrival times of the P-wave and S-wave on the continuous waveform on a long time scale. In DynaPicker, the 1D dynamic convolution decomposition (DCD) adapted from the work of Li et al. (2021b) on image classification is used as the backbone of the solution (see Fig. 1 for illustration).
In order to complete seismic body-wave phase classification and phase onset time picking, the main steps in this study are included as follows. First, the impact of different input data lengths on the performance of seismic phase detection and arrival-time picking are studied on the subset of the STanford EArthquake Dataset (STEAD) (Mousavi et al., 2019a). Then, the SCEDC dataset (Center, 2013) without specific phase arrival-time labeling collected by the Southern California Seismic Network is used to train and test the model in seismic phase identification. Finally, the pre-trained model is further applied to several open-source seismic datasets to evaluate the model performance in phase arrival-time picking performance. To this aim, in this study, the STEAD dataset (Mousavi et al., 2019a), the Italian seismic dataset for machine learning (INSTANCE) (Michelini et al., 2021), and the dataset across the Iquique region of northern Chile (Iquique) (Woollam et al., 2019) are used to verify the model performance in seismic phase picking.
The main contributions of this case study are summarized as follows:
-
This case study first introduces a deep-learning-based seismic phase identification solution, called “DynaPicker”, which is capable of reliably detecting P- and S-waves of even very small earthquakes, e.g., the local magnitude of the SCEDC dataset ranges from −0.81 to 5.7 ML.
-
The results tested on the data of varying lengths indicate that DynaPicker is adaptive to different lengths of input data for seismic phase identification. Moreover, it is proved that DynaPicker is robust in classifying seismic phases even when the seismic data are polluted by noise.
-
The testing data and the training data used for seismic phase identification and phase picking have no overlap, which proves that DynaPicker is capable of generalizing entire waveforms and metadata archives from different regions.
-
The CREIME model (Chakraborty et al., 2022b) is used to perform magnitude estimation for waveform windows for which the P-wave probability surpasses the threshold of 0.7. The results are highly dependent on this threshold, and it should be chosen after carefully looking at the data. It might also be necessary to use different thresholds for different stations.
In this study, we develop a 1D-DCD-based seismic phase classifier to handle seismic time series data. Our model takes a window of the normalized three-channel seismic waveform as input and predicts its label as P-phase, S-phase, or noise. Then, the pre-trained model is employed to automatically pick the arrival time on the continuous seismic data. Figure 1 schematically visualizes the proposed model architecture, which consists of convolutional layers, batch normalization, dropout, DCD-based layers, and a 1D dynamic classifier adapted from the work of Li et al. (2021b).
2.1 Dynamic convolution decomposition (DCD)
Dynamic convolution achieves a significant performance improvement over convolutional neural networks (CNNs) by adaptively aggregating K static convolution kernels (Yang et al., 2019; Chen et al., 2020). As shown in the paper by Li et al. (2021b), based on an input-dependent attention mechanism, dynamic convolution succeeds in aggregating multiple convolution kernels into a convolution weight matrix, which can be described as Eqs. (1) and (2):
where the attention scores {πk(x)} are used to linearly aggregate the K convolution kernels {Wk(x)}.
However, the vanilla dynamic convolution suffers from two main limitations: firstly, the use of K kernels will lead to the lack of compactness; secondly, it is challenging to jointly optimize the attention scores {πk(x)} and static kernels {Wk} (Li et al., 2021b).
To address the aforementioned issues, Li et al. (2021b) revisited dynamic convolution from a matrix decomposition viewpoint. They further proposed dynamic channel fusion to replace dynamic attention over the channel group to reduce the dimension of the latent space and to mitigate the difficulty of the joint optimization problem. An illustration of a DCD layer is given in Fig. 1. The general formulation of dynamic convolution using dynamic channel fusion is given as (Li et al., 2021b):
where Λ(x) represents a C×C diagonal matrix (C denotes the number of channels), and W0 denotes the static kernel. In the matrix Λ(x), the element λi,i(x) is a function of the input x. The matrix Φ(x) of size L×L fuses channels in the latent space ℝL associated with the dimensionality L dynamically. The two static matrices and are used to compress the input x into a low-dimensional space and expand the channel number to the output space, respectively (More details can be found in the paper by Li et al. (2021b)).
2.2 Seismic phase classifier network architecture
As presented in Fig. 1, the first convolutional layer is applied to process a three-channel window of seismic data in the time domain in order to generate a feature representation. Then, a batch normalization layer (BN) is used to accelerate the training process and provide stability for the network followed by an activation function using a rectified linear unit (ReLU) (Agarap, 2018). Finally, a max-pooling block (Simonyan and Zisserman, 2015) is added to reduce the size of the feature map, which is followed by a dropout layer (Srivastava et al., 2014) to avoid overfitting. The second part of the framework comprises several DCD-based layers, which are used to leverage favorable properties that are absent in static models. The right part of Fig. 1 shows the diagram of the 1D-DCD block, where a dynamic branch is used to produce coefficients for dynamic channel-wise attention Λ(x) of size C×C and dynamic channel fusion Φ(x) of size L×L (Li et al., 2021b). In the dynamic branch, the average pooling is first applied to the input x and then is followed by two fully connected (FC) layers associated with an activation layer between them. For the two FC layers used, the former aims to reduce the number of channels, and the latter tries to expand them into C+L2 outputs. Similar to a static convolution, a DCD layer also includes a BN and an activation (e.g., ReLU) layer followed by a dropout layer. Finally, the dynamic classifier uses this information to map the high-level features to a discrete probability over three categories (P-wave, S-wave, and noise wave). The dynamic classifier is also based on a 1D-DCD block.
It is worth noting that the model introduced in this study can be easily adapted to address inputs with different window sizes by simultaneously adjusting the sizes of the first layer and the dynamic classifier layer, respectively. With the goal of verifying the model robustness, the impact of different length data on seismic phase identification is investigated in the following section. The pre-trained model is extensively applied to pick arrival time on continuous data. The process of the arrival-time picking using different window sizes when feeding the same continuous seismic waveform is schematically visualized in Fig. 2.
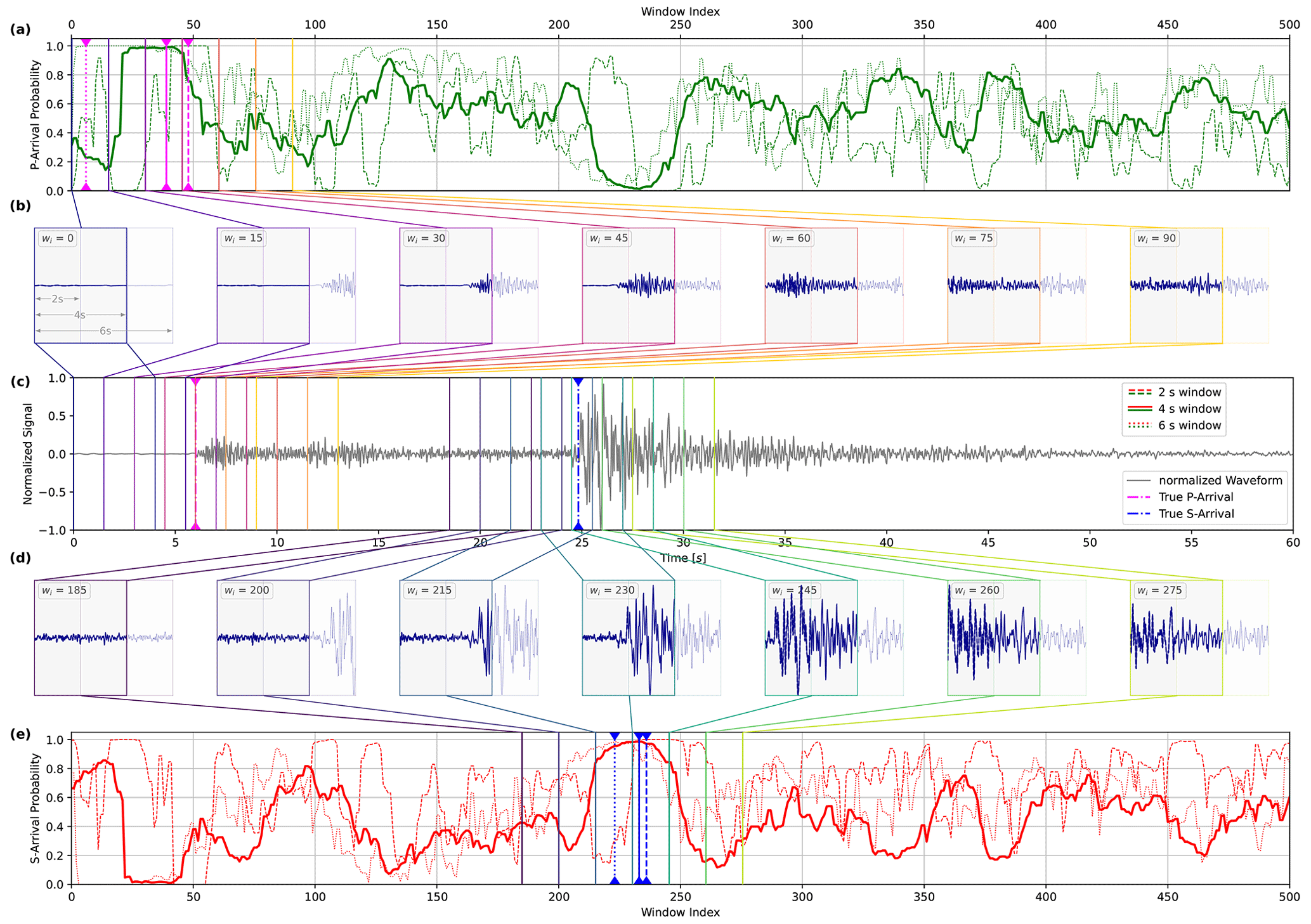
Figure 2Visualization of arrival-time picking using DynaPicker for a given normalized seismic waveform. Here, panel (c) shows only one channel of a real seismogram from the STEAD dataset (Mousavi et al., 2019a). The figure presents the model performance for different input window lengths of 2, 4, and 6 s; the windows are shifted by 10 samples at a time (for further details on this, refer to the Methodology section). The subsequent windows are denoted by different colors and shown explicitly in panels (b) and (d). Note that we only show specific windows around P- and S-arrivals in panels b and (d), respectively, as they are most relevant for the corresponding picks; (a) and (e) show the predicted probability of P-phase and S-phase arrivals, respectively, for the entire waveform. Each window visualized in panel b is mapped to a vertical line of the corresponding color in panel (a) at the window index wi representing that window. Similarly, each window visualized in panel (d) is mapped to a vertical line of the corresponding color in panel (e) at the window index representing that window. The dashed blue and pink vertical lines in panel (c) represent the true P-phase and S-phase arrival times (provided in the metadata for the dataset), respectively; analogously, the solid dashed and dotted blue vertical lines in panel (a) indicate the window indices corresponding to the predicted P-arrival for models trained on 4, 2, and 6 s windows, respectively, and the solid, dashed, and dotted pink vertical lines in panel (e) indicate the window indices corresponding to the predicted S-arrival for models trained on 4, 2, and 6 s windows, respectively. The P- and S-arrival samples are considered to be at the center of the picked windows.
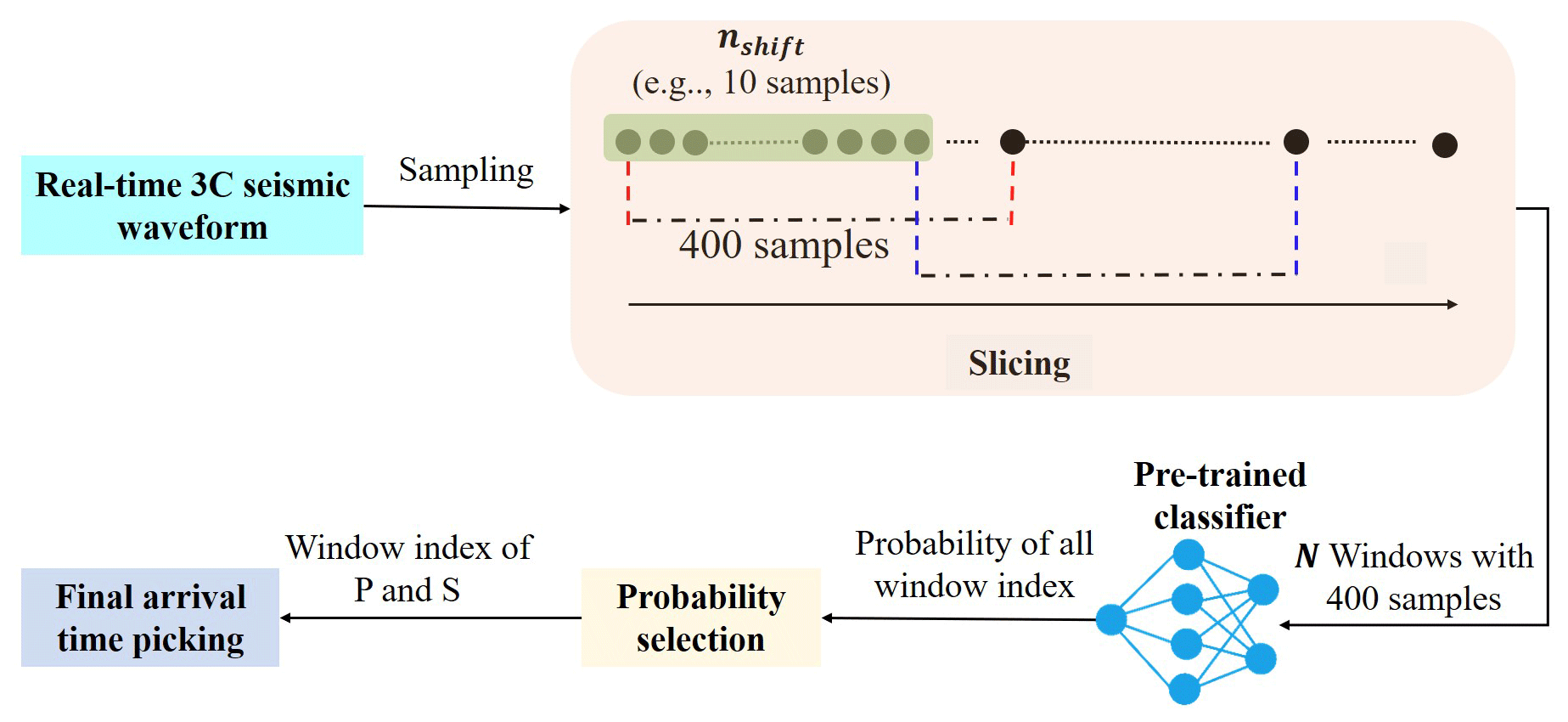
Figure 3Pipeline of arrival-time picking for continuous seismic waveforms given the pre-trained classifier.
2.3 Phase arrival-time estimation
To achieve seismic phase picking, the following steps are included, where the main steps are the same as in GPD (Ross et al., 2018) and CapsPhase (Saad and Chen, 2021). The pipeline for phase arrival-time picking on continuous seismic data using the pre-trained phase classifier is visualized in Fig. 3.
-
First, each waveform is filtered using the bandpass filter. For instance, the data from the STEAD dataset are filtered within the frequency range 2–20 Hz, following the CapsPhase (Saad and Chen, 2021).
-
Then, the waveform is sampled at 100 Hz followed by normalization using the absolute maximum amplitude. For example, for the STEAD dataset, each waveform has a size of 6000×3 after pre-processing.
-
Afterwards, the data of filtered are divided into several windows. Each window contains a 4 s three-component seismogram (400 samples since the sampling rate is 100 Hz), while the window strides with 10 samples such that the number of overlapping samples between neighbor windows is 390 samples. Therefore, the total number of windows is as follows:
where Ltotal and Lwin denote the length of the original waveform after sampling and the length of the window (e.g., 400 samples in this study), respectively. nshift is the number of the shift between windows in samples, and in this work it is empirically set as 10, the same as CapsPhase (Saad and Chen, 2021).
-
Then, the pre-trained classifier is utilized to predict three sequences of probabilities for each window associated with P-phase, S-phase, and noise, respectively. Following the work of Chen et al. (2020), a temperature softmax function (Goodfellow et al., 2016) is used in this study to smooth the output probability as follows:
where zk is the output of the classifier layer, and T is the temperature. The original softmax function is a special case when T=1. As T increases, the output is less sparse. In this study, the value of T is experimentally set to 41.
-
Finally, the arrival-time detection is declared using the following equation:
where Winindex denotes the window index of the largest probability, and tstart is the trace starting time. nc denotes the added constant that is 0.5× the window length for generalization since in the SCEDC dataset (Center, 2013) the P-wave and S-wave windows are centered around the arrival time.
In this work, the dataset provided by Southern California Earthquake Data Center (SCEDC) (Center, 2013) is used for model training and testing in seismic phase identification. The magnitude range of the data is . This dataset comprises 4.5 million three-component seismic signals with a duration of 4 s including 1.5 million P-phase picks, 1.5 million S-phase picks, and 1.5 million noise windows. The P-wave and S-wave windows are centered on the arrival pick, while each noise window is captured by starting 5 s before each P-wave arrival. Finally, the absolute maximum amplitude discovered on the three components is used to normalize each three-component seismic record. In this study, 90 % of the seismograms from the SCEDC dataset (Center, 2013) are used for model training, and the remaining 5 % of seismograms are employed to test the model performance. Furthermore, we compare the seismic phase classification performance with a capsule neural network-based seismic data classification approach, termed “CapsPhase” (Saad and Chen, 2021), and our previous work, 1D-ResNet (Li et al., 2022b).
To achieve seismic phase identification, DynaPicker takes a window of three-channel waveform seismogram data as input, and then for each input, the model predicts the probabilities corresponding to each class (P-wave, S-wave, or noise). This model has three output labels: zero for the P-wave window, one for the S-wave window, and two for the noise window.
In order to further evaluate the model performance in phase arrival-time picking pre-trained on the SCEDC dataset (Center, 2013), several subsets of three open-source public seismic datasets, namely, the STEAD dataset (Mousavi et al., 2019a), the INSTANCE dataset (Michelini et al., 2021), and the Iquique dataset (Woollam et al., 2019), are used. Each waveform in the first two datasets is either 1 or 2 min long. They can be viewed as good generalization tests of our proposed method. DynaPicker is compared with the generalized phase detection (GPD) framework (Ross et al., 2018) based on CNNs, CapsPhase (Saad and Chen, 2021) based on capsule neural networks (Sabour et al., 2017), and AR picker (Akazawa, 2004) to evaluate the performance of phase arrival-time picking on continuous seismic recordings.
In this article, noise labels are not treated differently from phase labels, and thus classifying a noise window correctly has the same weight as confirming a phase window. The seismic phase detector can be viewed as a three-class classifier that decides whether a given time window contains a seismic phase (P or S) or only noise. Here, the “noise” windows do not contain P- or S-phases. We can evaluate a deep-learning model by processing labeled testing data where the true output is known. The accuracy defined below is a simple measure of a classifier’s performance:
where NC denotes the number of correctly labeled samples and NT represents the total number of testing samples.
To evaluate the detector’s effectiveness, a confusion matrix (Stehman, 1997) is adopted to reflect the classification result, and then precision and recall can be defined as follows:
The F1-score is computed from the harmonic mean of precision and recall for each class:
where TN, FN, FP, and TP are the number of true negative, false negative, false positive, and true positive, respectively.
5.1 Seismic phase classifier training
In this study, for dynamic convolution decomposition units, all the weight and filter matrices are initialized with a normal initializer and bias vectors set to zeros. For optimization, we use the ADAM (Kingma and Ba, 2014) algorithm, which keeps track of first- and second-order moments of the gradients and was invariant to any diagonal rescaling of the gradients. We used a learning rate of 10−3 and trained the DynaPicker for 50 epochs, the same as CapsPhase (Saad and Chen, 2021). In this work, DynaPicker was implemented in PyTorch (Paszke et al., 2019), and all the training was performed on an NVIDIA A100 GPU. The model was trained using a cross-entropy loss function with the ADAM optimization algorithm, in mini-batches of 480 records. We used a dropout rate of 0.2 for all dropout layers.
5.2 Investigation of different input data lengths
Here, we investigate the impact of different input data lengths on the performance of seismic phase detection and arrival-time picking using the STEAD dataset. The details of arrival-time picking using a pre-trained phase classifier can be found in the following subsections and the Methodology section.
5.2.1 Different length of the input data on phase classification
To this end, we select 58 018 earthquake waveforms from the STEAD dataset (Mousavi et al., 2019a) and create three datasets within different durations (2, 4, and 6 s). There is a total of 174 054 waveforms including P-wave, S-wave, and noise wave in each dataset. In this experiment, all data are re-sampled at 100 Hz and each three-component waveform is normalized by the absolute maximum amplitude observed on any of the three components. Similar to the SCEDC dataset (Center, 2013), P-wave and S-wave windows are centered on the respective arrival-time picks. Noise windows are captured from pure noise waveforms. Note that these three datasets consist of the same events, and only the window length is different.
Then, each dataset is split into a training dataset (90 %) and a testing dataset (10 %). The overall testing accuracy for different-length input data is estimated to be 95.52 %, 97.99 %, and 98.02 % in line with 2, 4, and 6 s, respectively. The result demonstrates that DynaPicker can work well with the input of different time durations.
The confusion matrices corresponding to the input data with different duration are shown in Fig. 4. We can observe that the model developed here reaches a high detection accuracy for each class, especially in noise window detection as shown in Fig. 4, where noise waveform is more easily distinguishable from P and S arrivals than they are from each other in the cases of 4 and 6 s data.
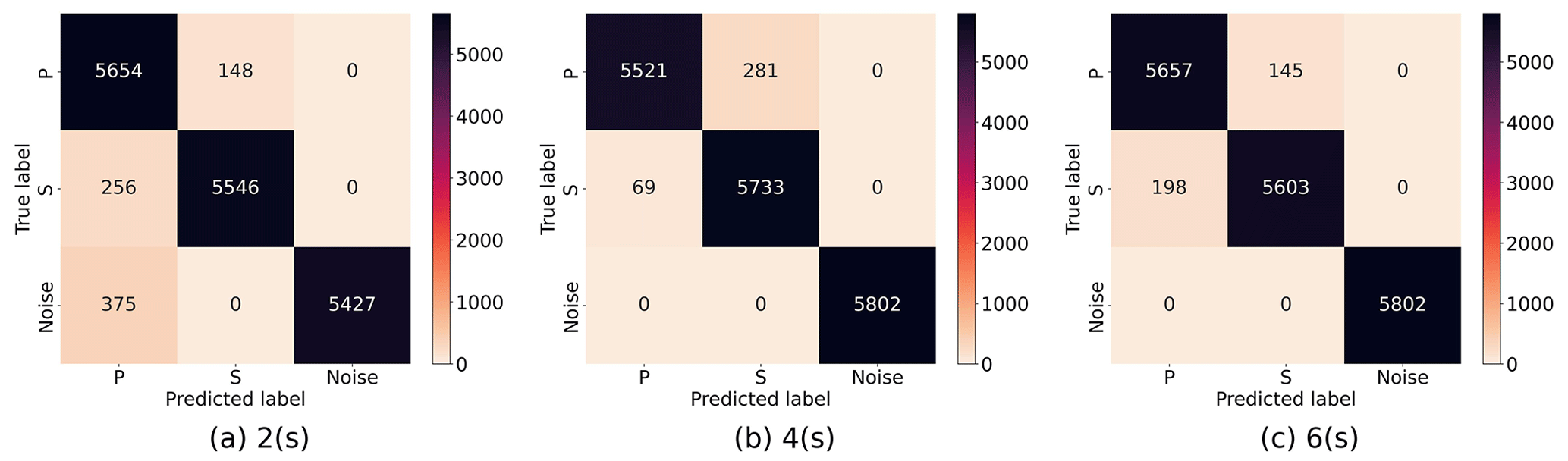
Figure 4Confusion matrices for seismic phase classification given different input data lengths: (a) 2 s, (b) 4 s, and (c) 6 s using DynaPicker.
In the end, the testing results indicate that our model is adaptive to different lengths of input data. At the same time, our model achieves a compatible performance in seismic phase picking even with low-volume training data.
5.2.2 The impact of different lengths of input data for continuous seismic records
In this part, the pre-trained DynaPicker on the seismic data with different time duration is further evaluated on continuous seismic data. Moreover, the model is compared with EPick (Li et al., 2022a), a simple neural network that incorporates an attention mechanism into a U-shaped neural network. Here, the pre-trained and saved model of EPick is directly used without retraining. Besides, there is no overlap between the training data used for seismic phase identification and the data adopted in testing the model performance in phase picking. The testing results are summarized in Table 1. Here, we can observe that EPick achieves the best performance in phase picking over DynaPicker by using different window sizes. The potential reason is that EPick is pre-trained on the data labeled with the specific phase arrival time from the STEAD dataset. Secondly, a larger window size reduces the number of the P-phase with an error less than 0.5 s. Thirdly, in the case where the window size is 4 s, the number of the S-phase with an error less than 0.5 s is larger than in the other two cases, e.g., 2 and 6 s.
Table 1Body-wave arrival-time evaluation using different window lengths on the STEAD dataset.
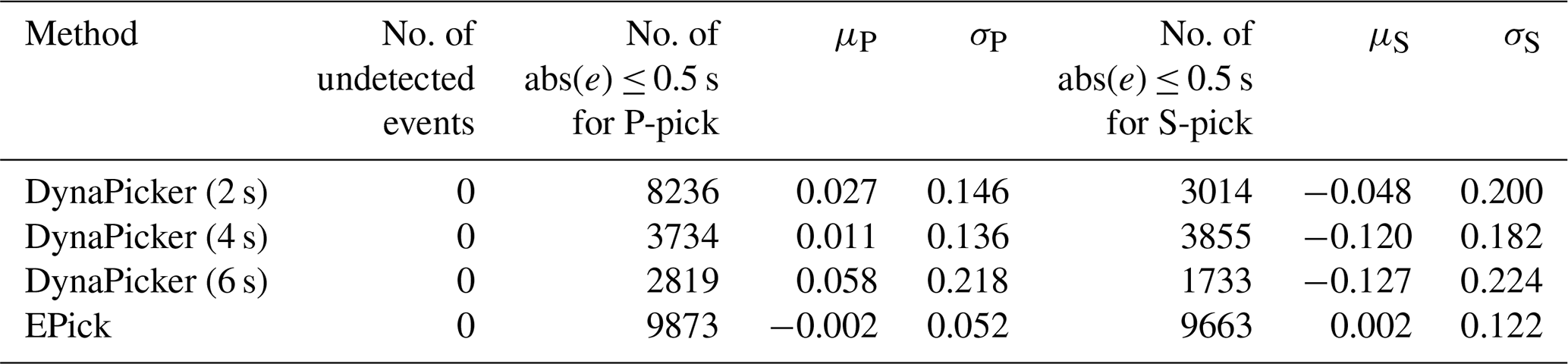
μP and σP are the mean and standard deviation of errors (ground truth − prediction) in seconds, respectively, for P-phase picking. μS and σS are the mean and standard deviation of errors (ground truth − prediction) in seconds, respectively, for S-phase picking.
5.3 Seismic phase classification on 4 s SCEDC dataset
As discussed in the previous subsections, the proposed model, DynaPicker, can be adapted to the data with different lengths and achieves compatible performance.
Here, DynaPicker is further retrained and tested on the SCEDC dataset (Center, 2013) collected by the Southern California Seismic Network (SCSN) 2. Then, we compared our model with CapsPhase (Saad and Chen, 2021) and our previous work, 1D-ResNet (Li et al., 2022b), with the same test set. The testing accuracy of DynaPicker is 98.82 %, which is slightly greater than CapsPhase (Saad and Chen, 2021) (98.66 %) and 1D-ResNet (Li et al., 2022b) (98.66 %).
Different evaluation metrics, such as the Precision, Recall, and F1-score for DynaPicker, CapsPhase (Saad and Chen, 2021), and 1D-ResNet (Li et al., 2022b), are summarized in Table 2. As one can see from Table 2, compared with the baseline methods, DynaPicker can achieve superior performance in terms of the F1-score. For precision and recall, DynaPicker also achieves a comparable performance.
Saad and Chen (2021)Li et al. (2022b)Saad and Chen (2021)Li et al. (2022b)Saad and Chen (2021)Li et al. (2022b)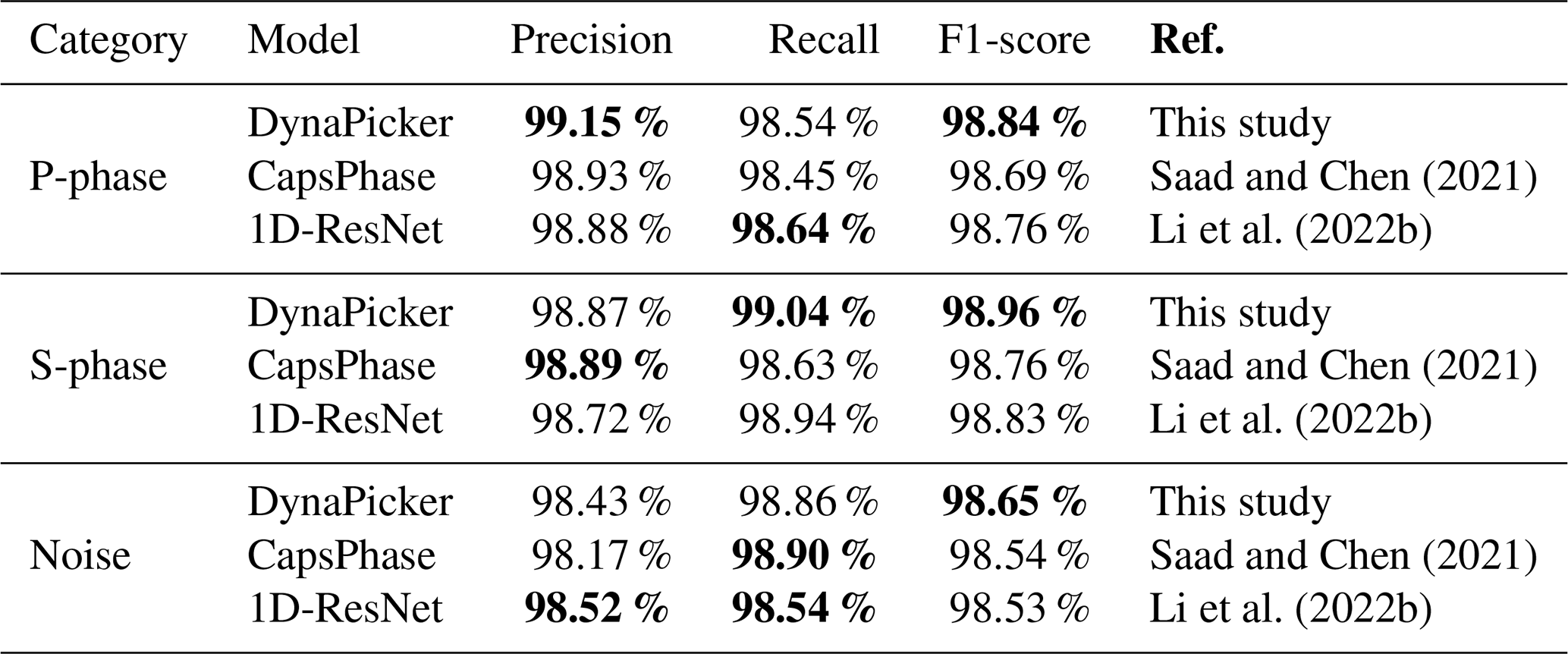
The best-saved model of CapsPhase is directly used here without retraining and, unlike the original CapsPhase(Saad and Chen, 2021), the output threshold for each class is not used in this work since it reduces the CapsPhase performance in the testing phase. Bold values represent the best performance.
Finally, in order to investigate the model performance when facing more noisy data, the same subset selected from the STEAD dataset used in 1D-ResNet (Li et al., 2022b) is utilized. Here, the signal-to-noise ratio (SNR) of the selected data before adding noise ranges from 0 to 70 dB, and the SNR is the mean value of SNR over three components for each signal. The magnitude of the data ranges from 1.0 to 3.0. To study the impact of different noise levels on model performance, the subset is masked by the Gaussian noise (similar to the method used in EQTransformer (Mousavi et al., 2020)) with mean μ=0 and standard deviation δ= 0.01, 0.05, 0.1, and 0.15, respectively. Afterward, these noisy data are fed to the pre-trained phase classifier to test the model performance. The testing accuracies of different models are summarized in Table 3. The results in Table 3 show that (a) large noise reduces the model performance, (b) DynaPicker outperforms CapsPhase and 1D-ResNet, and (c) DynaPicker is robust in identifying seismic phases when the seismic data are polluted by noise.
(Saad and Chen, 2021)(Li et al., 2022b)Table 3Testing results of different noise levels for phase identification on the STEAD dataset.

The best-saved model of CapsPhase is directly used here without retraining and unlike the original CapsPhase (Saad and Chen, 2021), the output threshold for each class is not used in this work since it reduces the CapsPhase performance in the testing phase. Bold values represent the best performance.
5.4 Seismic arrival-time picking on continuous seismic records
We next demonstrate the applicability of our model to pick the seismic phase arrival time for continuous seismic data in the time domain. The main parameters related to phase arrival-time picking are studied in the following section. In this work, DynaPicker is implemented for seismic phase identification given short-window seismic waveforms same as GPD and CapsPhase. Hence, DynaPicker is first compared with two window-based methods including GPD and CapsPhase on both the STEAD dataset and the INSTANCE dataset. Second, we compare DynaPicker with one of the state-of-the-art sample-based seismic phase pickers, EQTransformer (Mousavi et al., 2020), on the Iquique dataset (Woollam et al., 2019). The reason is that, on the one hand, EQTransformer is a multi-task deep-learning model designed for earthquake detection and seismic phase picking, which is trained on the STEAD dataset labeled with specific phase arrival time. On the other hand, the original INSTANCE paper (Michelini et al., 2021) reported that EQTransformer is used in picking the first arrivals of P- and S- waves. Therefore, in this study, the subset of the Iquique dataset (Woollam et al., 2019) is further applied to achieve a fair comparison between DynaPicker and EQTransformer.
Table 4Body-wave arrival-time evaluation using different methods on STEAD dataset including (a) 4 s and (b) 4 s. In each case, 1×104 samples are used. Following Saad and Chen (2021), the event whose pick predicted by a model has an absolute error larger than 0.5 s is recognized as false positive.
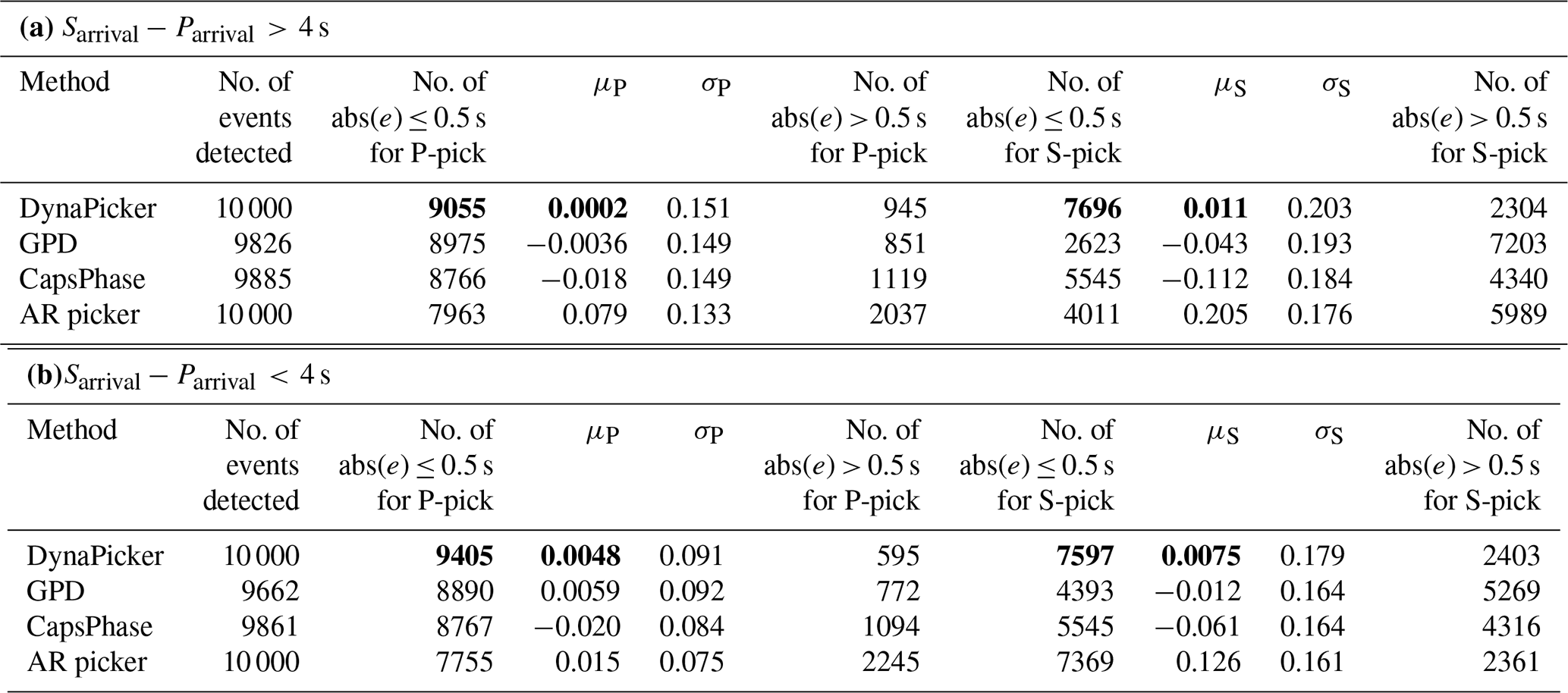
μP and σP are the mean and standard deviation of errors (ground truth − prediction) in seconds, respectively, for P-phase picking. μS and σS are the mean and standard deviation of errors (ground truth − prediction) in seconds, respectively, for S-phase picking. Bold values represent the best performance.
5.4.1 Comparison with window-based methods
-
Application to the STEAD dataset. We randomly select 2×104 earthquake waveforms from the STEAD dataset, out of which 1×104 have a time difference greater than 4 s between P-wave arrival and S-wave arrival, while for the remainder this difference is less than 4 s and the epicentral distances are less than or equal to 35 km. Here we use 4 s as the threshold for waveform selection since the SCEDC dataset (Center, 2013) with the duration of 4 s is used to train and test the model performance on seismic phase classification. To study the impact of the time difference between P and S picks, the events of different time differences are used to verify the robustness of our model in seismic arrival-time picking for continuous seismic data.
As presented in GPD (Ross et al., 2018) and CapsPhase (Saad and Chen, 2021), a triggering method is used to locate arrival picks by setting a threshold. However, the picking performance is impacted by the threshold. To overcome this drawback we use the window index with the largest probability to locate the P and S picks as this empirically yields the best results.
Table 4 summarizes the testing results of arrival-time picking on the STEAD dataset. From Table 4, we can see that (a) our model succeeds in correctly detecting all seismic events, while about 174 and 115 seismic events cannot be detected by GPD (Ross et al., 2018) and CapsPhase (Saad and Chen, 2021) for the earthquake signal with s, and about 338 and 139 seismic events cannot be detected by GPD (Ross et al., 2018) and CapsPhase (Saad and Chen, 2021) for the earthquake signal with s; (b) compared with GPD (Ross et al., 2018), CapsPhase (Saad and Chen, 2021), and AR picker (Akazawa, 2004), most of the error between the located P-wave or S-wave picks and the ground truth are within 0.5 s when using DynaPicker. We use 0.5 s for our analysis following CapsPhase (Saad and Chen, 2021); (c) DynaPicker is robust for seismic events of different time differences between P and S picks. In summary, our proposed model outperforms the baseline methods.
-
Application to the INSTANCE dataset. We also evaluate the picking performance of our model using the INSTANCE dataset (Michelini et al., 2021) and compare the picking error with the benchmark methods. This dataset includes about 1.2 million three-component waveforms from about 5×104 earthquake events recorded by the Italian National Seismic Network. In the metadata, the recorded earthquake list ranges from January 2005 to January 2020, and the magnitude of the earthquake events ranges from 0.0 to 6.5. All the recorded seismic waveforms have a duration of 120 s and are sampled at 100 Hz. We randomly select 2×104 earthquake waveforms from the INSTANCE dataset (Michelini et al., 2021), out of which 1×104 have a time difference greater than 4 s between P-wave arrival and S-wave arrival, while for the remainder this difference is less than 4 s and similarly, the epicentral distances are less than or equal to 35 km.
As summarized in Table 5, we can observe that the proposed model outperforms the baseline methods. On one hand, the proposed model succeeds in identifying the true label corresponding to each input, which means all seismic events are detected compared with the baseline methods used. On the other hand, our model achieves a lower arrival-time picking error, and it is robust for different time differences between P and S picks. In particular, our model achieves the lowest mean error in S-phase arrival-time picking for both cases.
Table 5Body-wave arrival-time evaluation using different methods on INSTANCE dataset including (a) 4 s and (b) 4 s. In each case, 1×104 samples are used. Following Saad and Chen (2021), the event whose pick predicted by a model has an absolute error larger than 0.5 s is recognized as false positive.
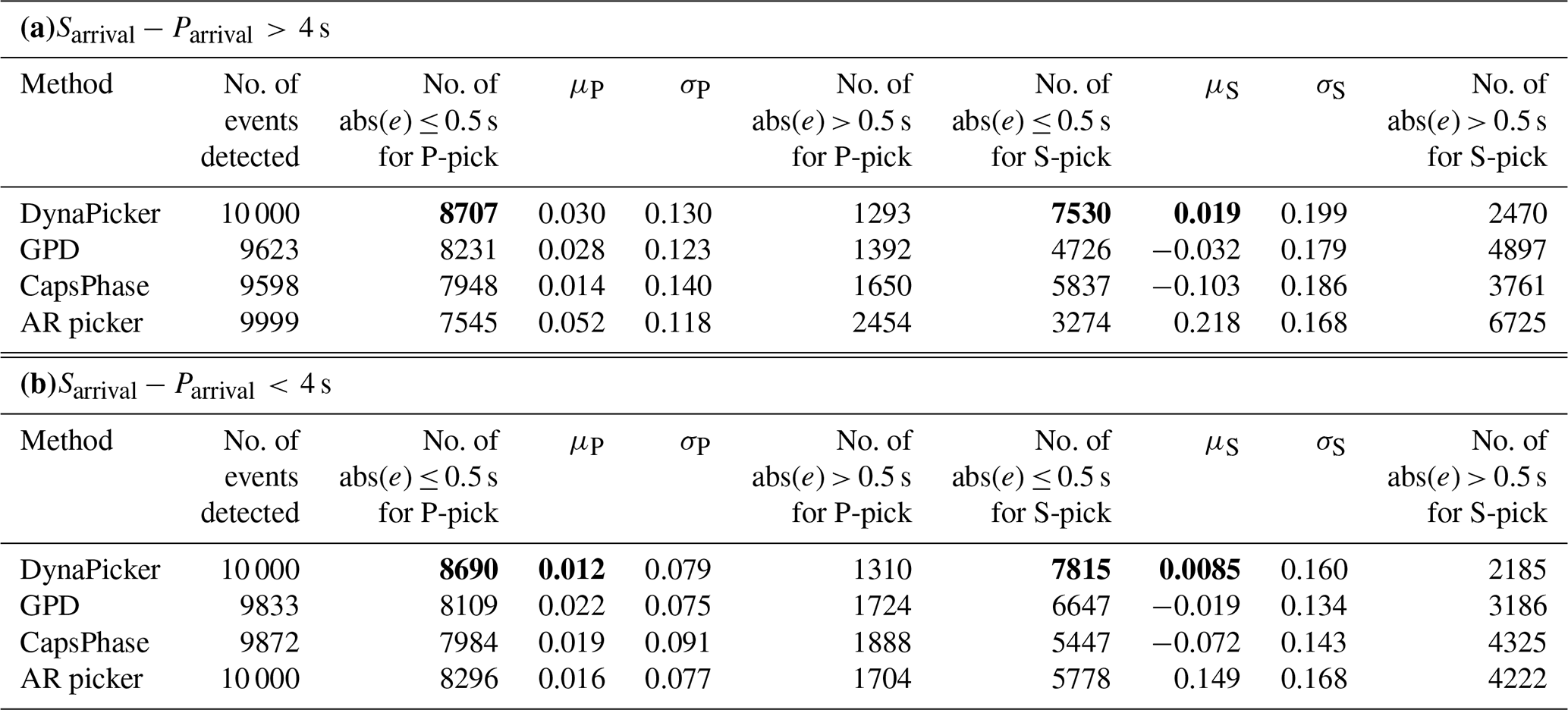
μP and σP are the mean and standard deviation of errors (ground truth − prediction) in seconds, respectively, for P-phase picking. μS and σS are the mean and standard deviation of errors (ground truth − prediction) in seconds, respectively, for S-phase picking. Bold values represent the best performance.
5.4.2 Comparison with sample-based method
The Iquique dataset comprises locally recorded seismic arrivals throughout northern Chile and is used in several previous studies (Woollam et al., 2019, 2022; Münchmeyer et al., 2022) to train a deep-learning-based picker. It contains about 1.1×104 manually picked P-/S-phase pairs, where all the seismic waveform units are recorded in counts. In this study, 1×104 P-/S-phase pairs are used, and DynaPicker is further compared with the advanced deep-learning model Earthquake transformer (EQTransformer) (Mousavi et al., 2020) to evaluate onset picking. In particular, it is worth noting that neither DynaPicker nor EQTransformer is retrained on the Iquique dataset.
First, the confusion matrices for P- and S-phase arrival picking results of the experiment using DynaPicker and EQTransformer are shown in Fig. 5a and b. We find that out of the selected 1×104 signals, EQTransformer misses 243 events, which means that for these misclassified earthquake events, no arrival pick is detected. Compared with EQTransformer, DynaPicker is capable of detecting all earthquake events including all P-phase and S-phase arrival-time pairs.
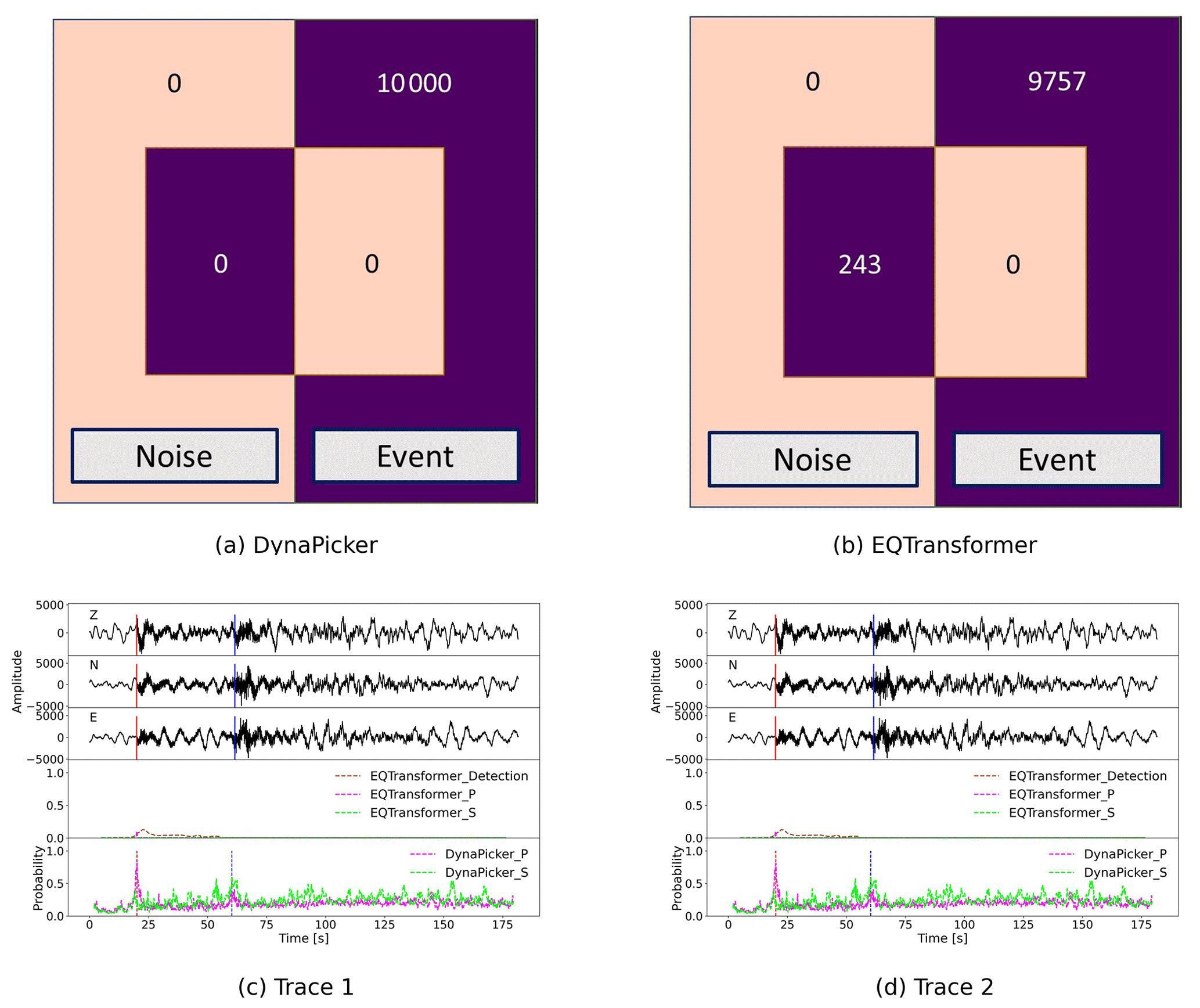
Figure 5Visualizations of the testing result on the Iquique dataset. In (a) and (b) the confusion matrices from in-domain experiments for DynaPicker and EQTransformer, respectively, are shown. Here, the pre-trained model of EQTransformer is directly used without retraining and adopted from Seisbench (Woollam et al., 2022), where DynaPicker is able to detect all earthquake events compared with EQTransformer. Panels (c) and (d) plot the EQTransformer and DynaPicker predictions on two waveform examples from the Iquique dataset. In (c) and (d), the upper three subplots are the three-component seismic waveforms where the red and blue vertical lines correspond to the ground truth arrival time of P- and S-phases from the dataset metadata, respectively, and the bottom subplots display the predicted probability for P- and S-phases by using EQTransformer and DynaPicker, respectively, where the dashed vertical lines in red and blue depict the locations of the maximal predicted probabilities of P- and S-phases, respectively. For EQTransformer, in (c) only the P-pick is detected at a low probability, whereas the S-pick is missing, and in (d) multiple picks are predicted, in particular one incorrectly detected P-phase is detected at a high probability. For DynaPicker, both the true P- and S-phases are detected with a higher probability compared with EQTransformer.
Two examples from the Iquique dataset using EQTransformer and DynaPicker are displayed in Fig. 5c and d, respectively. The picking result of EQTransformer is implemented by using Seisbench (Woollam et al., 2022), and in DynaPicker, only the sample of the largest probability is recognized as P- or S-phases. It can be observed that in Fig. 5c the P-phase detected by EQTransformer is with a low probability, and the S-phase is missing, while the P-phase estimated by DynaPicker is of high probability, and S-phase is also detected as shown in the bottom subplot of Fig. 5c. In Fig. 5d, EQTransformer detects multiple picks including one incorrectly detected P-phase, and DynaPicker also picks multiple P-phase and S-phases. In contrast to EQTransformer, in DynaPicker only the sample with the largest probability is regarded as the true prediction for both P- and S-phases. However, as shown in the bottom subplot of Fig. 5d, DynaPicker is capable of determining the truly predicted P- and S-phases with a larger probability compared to EQTransformer.
Finally, the absolute error between deep-learning-based model-predicted picks (e.g., EQTransformer and DynaPicker) and manual picks that are below 0.5 s is taken into account. For both P- and S-waves, EQTransformer performs slightly better than DynaPicker in terms of both the root mean square error (RMSE) and the mean absolute error (MAE). Here, the MAE and RMSE of both P- and S-waves using EQTransformer are MAE(P) =0.091 s, RMSE(P) =0.095 and MAE(S) =0.159 s, and RMSE(S) =0.126 s. And the MAE and RMSE of both P- and S-waves using DynaPicker are MAE(P) =0.127 s, RMSE(P) =0.128 s, and MAE(S) =0.198 s, RMSE(S) =0.137 s. However, it is worth noting that the original EQTransformer is trained on labeled arrival-time seismic data of the STEAD dataset, while DynaPicker is only trained on the short-window SCEDC dataset without phase arrival-time labeling.
5.5 Earthquake detection
In this subsection, we further test the performance of DynaPicker in P-wave onset detection using the published CREIME model (Chakraborty et al., 2022b) for magnitude estimation. We selected varying time intervals of data recorded on 6 February 2023 to test the detection of diverse aftershocks (see Table B1). The data correspond to seismograms from stations that are part of the seismic network operated by the Kandilli Observatory and Earthquake Research Institute, known as KOERI (Kandilli Observatory And Earthquake Research Institute, Boğaziçi University, 1971). The information regarding arrival times, locations, and magnitude estimations was obtained from the catalog of the Bogazici University Kandilli Observatory and Earthquake Research Institute National Earthquake Monitoring Center.
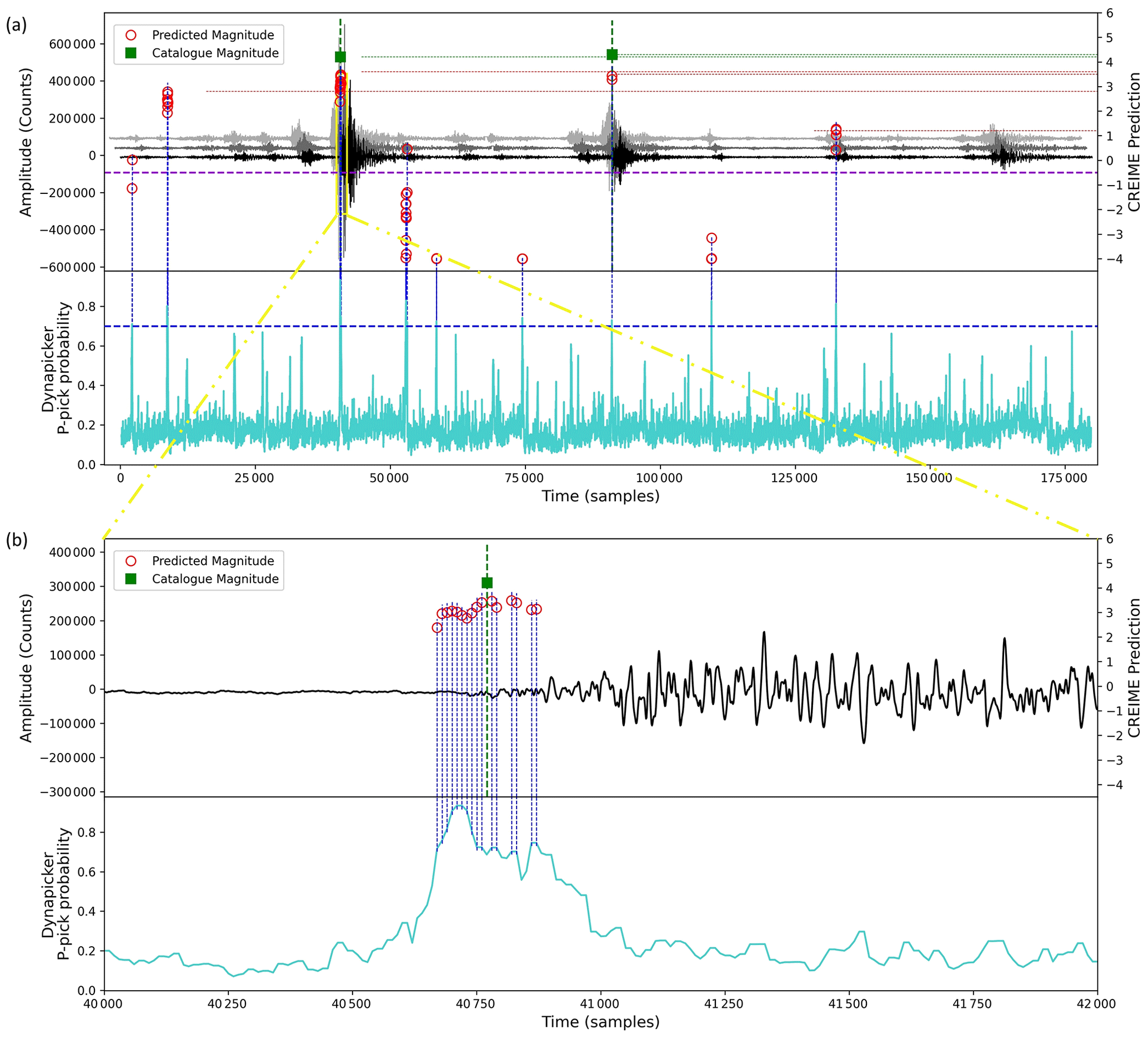
Figure 6A visualization for combining DynaPicker and CREIME on a seismic recording. DynaPicker uses three-component waveforms to output probabilities corresponding to P- and S-arrivals. The waveform windows with a P-pick probability higher than 0.7 are fed to the CREIME model for magnitude estimation. The red circles represent CREIME predictions while the green squares represent catalog magnitude. A CREIME prediction of less than −0.5 (marked with the dashed purple line in (a)) represents noise. Please note that the time axis correlates with the Z component of the seismogram, shown in black.
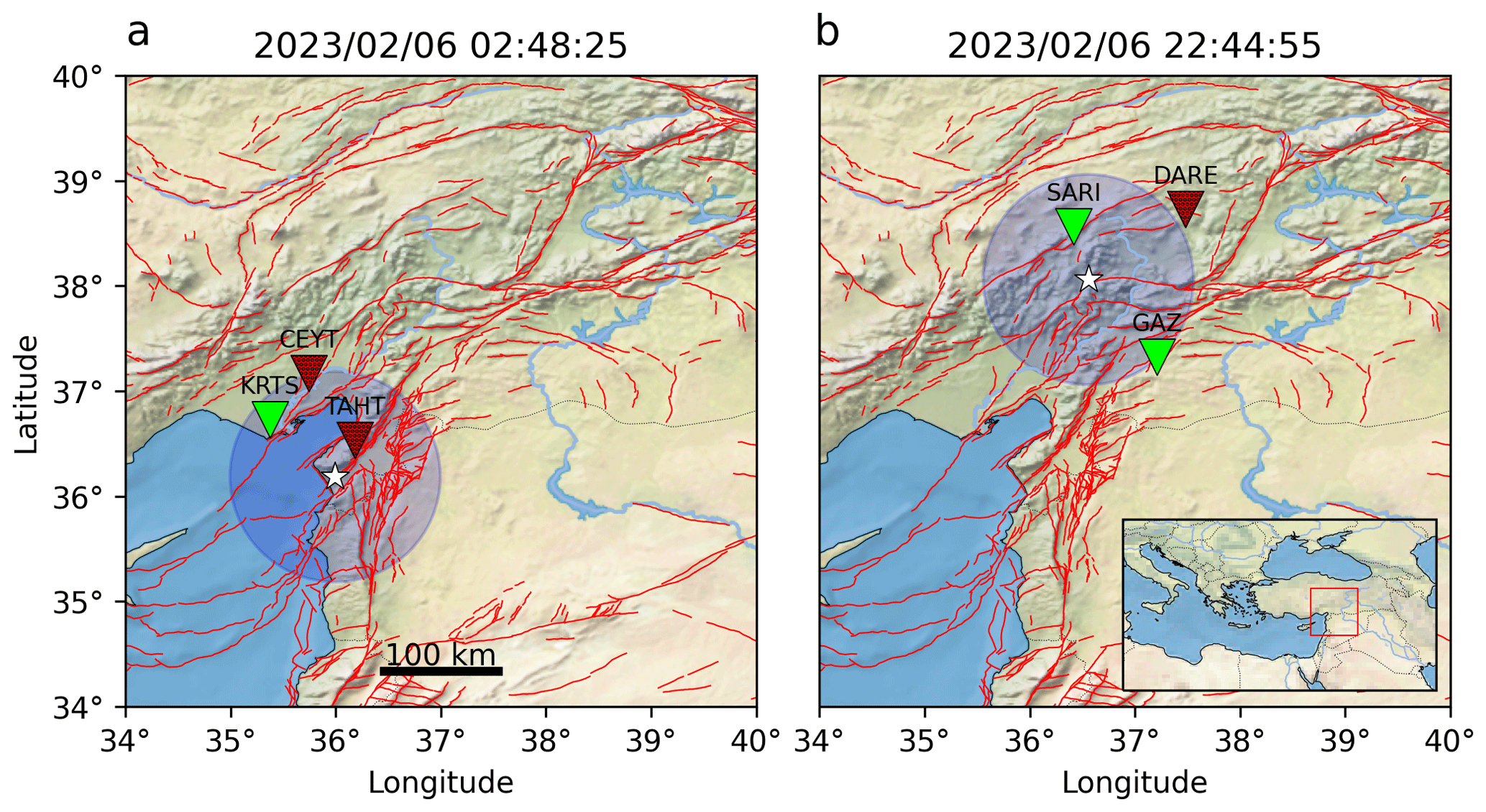
Figure 7Two example earthquakes from the recent Turkey earthquake series and how they were detected using DynaPicker. Green stations correspond to a successful detection, and dotted red ones to an unsuccessful detection. The earthquake epicenter is marked with a star, together with a 1∘ radius around it, the targeted range for DynaPicker. Additionally, we show the active faults in the region, as taken from Zelenin et al. (2022), with red lines.
We begin by feeding the aftershock waveform of the 2023 Turkey earthquake data into DynaPicker to obtain the P-phase probabilities for each sample. We then use both the waveform windows for which the P-phase probability exceeds 0.7 as input for the CREIME model to estimate the magnitude of the aftershocks. Finally, a seismological expert cross validates the estimated magnitude with the Turkey earthquake catalog (see Table B1). The results of this analysis are presented in Fig. 6. The waveform is first analyzed by DynaPicker. Subsequently, the windows for which DynaPicker P-pick probability is higher than 0.7 are fed to the CREIME model for magnitude estimation. The magnitudes predicted by CREIME are shown by the red circles in Fig. 6 and the catalog magnitudes are shown by the purple squares. A slight underestimation is observed, which can be attributed to noise in the data and the use of different magnitude scales. This will be looked into in future works. A predicted magnitude of less than −0.5 by CREIME represents noise. Figure 7 shows two earthquakes that had at least three stations within 1∘. One earthquake is successfully detected at two stations while the other is detected only in one station.
6.1 Model retraining
We also performed retraining on all the models, including DynaPicker, GPD, and CapsPhase, using the SCEDC dataset and applying the early stopping technique, the same as GPD (Ross et al., 2018) and CapsPhase (Saad and Chen, 2021). The SCEDC dataset was divided randomly into a training dataset (90 %), a validation dataset (5 %), and a testing dataset (5 %). Besides, different from the original DynaPicker, here we employ a large kernel size and replace the first static convolution layer with the 1D-DCD block. The testing results for three models are as follows: DynaPicker, 98.96 %; GPD, 98.85 %; and CapsPhase, 98.45 %. The results indicate that incorporating a larger kernel size and replacing the initial static convolution layer with the 1D-DCD block in the original DynaPicker model indeed contribute to improving its performance. However, these modifications did not result in a significant enhancement for DynaPicker. Conversely, the accuracy of CapsPhase was observed to be lower compared to the reported findings in the original paper (Saad and Chen, 2021). Moreover, the retrained versions of DynaPicker and GPD exhibit a greater margin of error when it comes to seismic phase picking, in contrast to the original DynaPicker and the pre-trained GPD (Ross et al., 2018). Consequently, for the seismic phase picking task in this study, we will utilize the pre-trained models of GPD and CapsPhase.
6.2 Challenges
In Table B1, it is noted that in some cases, DynaPicker struggles to detect the phase pick for the continuous waveforms of the Turkey earthquake. These challenges necessitate further investigation and improvement in future endeavors. Firstly, DynaPicker divides the continuous seismic record into 4 s overlapping windows, which means its detection performance depends on the arrival-time difference between P- and S-phases and on the shifted numbers applied. Secondly, when evaluating the magnitude using CREIME, there seems to be an underestimation of the magnitude compared to the catalog values. This discrepancy could be attributed to data noise or variations in magnitude scales utilized in the catalog. Last but not least, the data fed for DynaPicker are filtered by the bandpass filter; hence, the picking performance is contingent upon the quality of the seismic data. Our forthcoming work aims to address these challenges comprehensively.
This study first introduces a novel seismic phase classifier based on dynamic CNN, which is subsequently integrated into a deep-learning model for magnitude estimation. The classifier consists of a conventional convolution layer and multiple dynamic convolution decomposition layers. To train the proposed seismic phase classifier, we use seismic data collected by the Southern California Seismic Network. The classifier exhibits promising results during testing with earthquake waveforms recorded globally, demonstrating its good generalization ability. Extensive experiments demonstrate that this model yields a superior performance over several baseline methods on phase identification and phase picking. The results from our work contribute to the existing body of literature on supervised deep-learning-based methods for seismic phase classification and demonstrate that with appropriate considerations regarding overfitting and generalization, such methods can improve seismological processing workflows, not just for large catalogs, but also for varying datasets. Moreover, the proposed model is further validated for the monitoring task of the 2023 Turkey earthquake aftershocks.
In this part, the impact of different temperatures in the softmax function (see Eq. 5 for illustration) and the different shift numbers (nshift) on the model performance of phase arrival-time picking for continuous seismic waves is investigated. Here, 1×104 samples are randomly selected from the STEAD dataset (Mousavi et al., 2019a). The distribution of earthquake magnitudes, earthquake source depth, earthquake source distance, and time difference between P-phase and S-phase arrival time are displayed in Fig. A1.
A1 Impact of different temperatures
In this part, the impact of different temperatures in the softmax function used on the model performance of phase arrival-time picking for the continuous seismic wave is investigated, as summarized in Table A1, in which nshift is fixed as 10. From Table A1, in this work the temperature T is empirically set to 4.
A2 Impact of shift numbers
This part studies the effect of different shift numbers (nshift) on seismic onset arrival-time estimation, where the temperature T is set to 4. From Table A2, we can conclude that the results of nshift=5 and nshift=10 are close, while according to Eq. (4), a lower shift number increases the number of sliding windows, and more time is used to locate the arrival- time. Hence, in this study, the shift number nshift is set as 10.
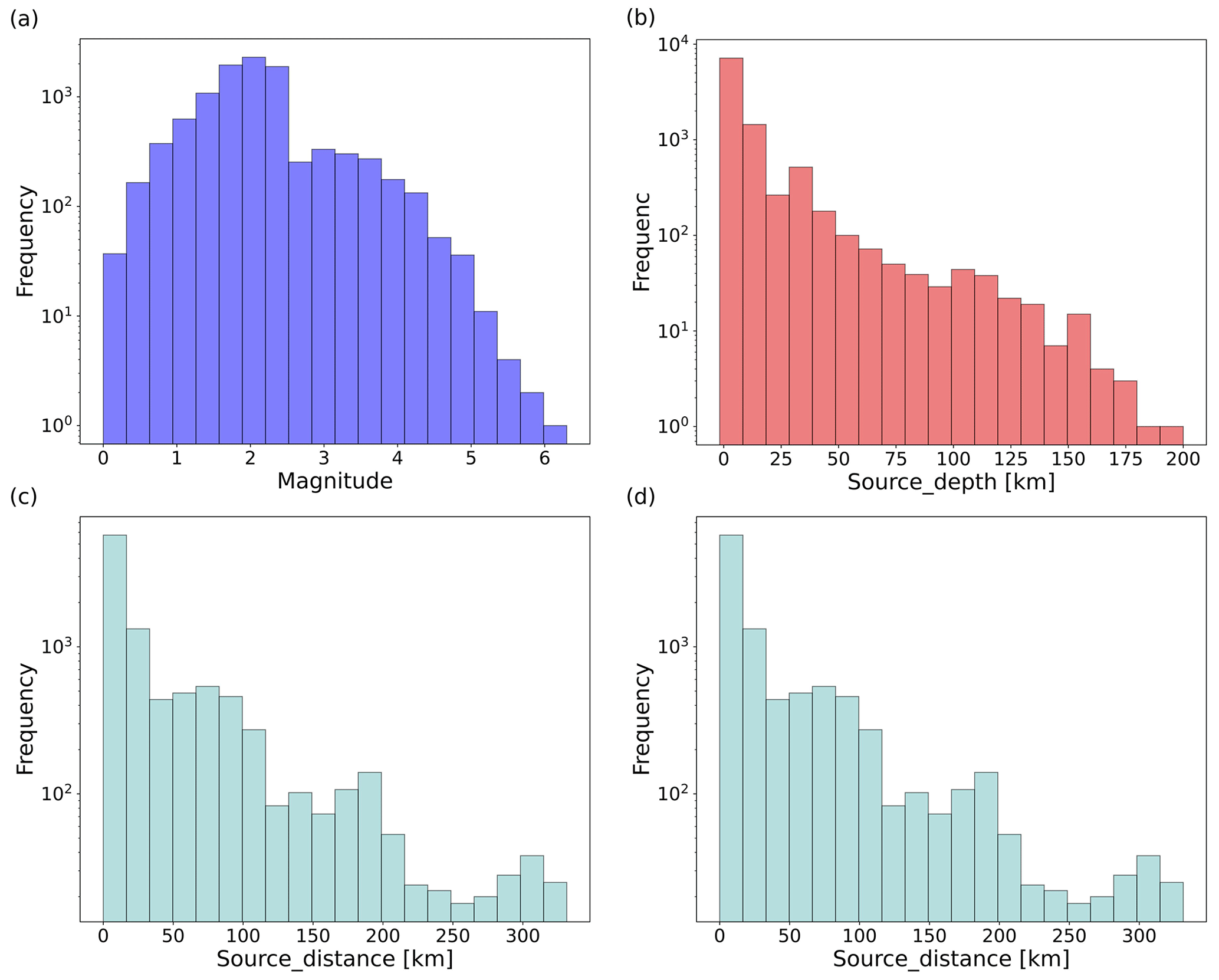
Figure A1Distribution of (a) earthquake magnitudes, (b) earthquake source depths, (c) earthquake source distances, and (d) time difference between P-phase and S-phase arrival time of the subset from the STEAD dataset (Mousavi et al., 2019a).
Table A1Body-wave arrival-time evaluation using different temperatures on the STEAD dataset.
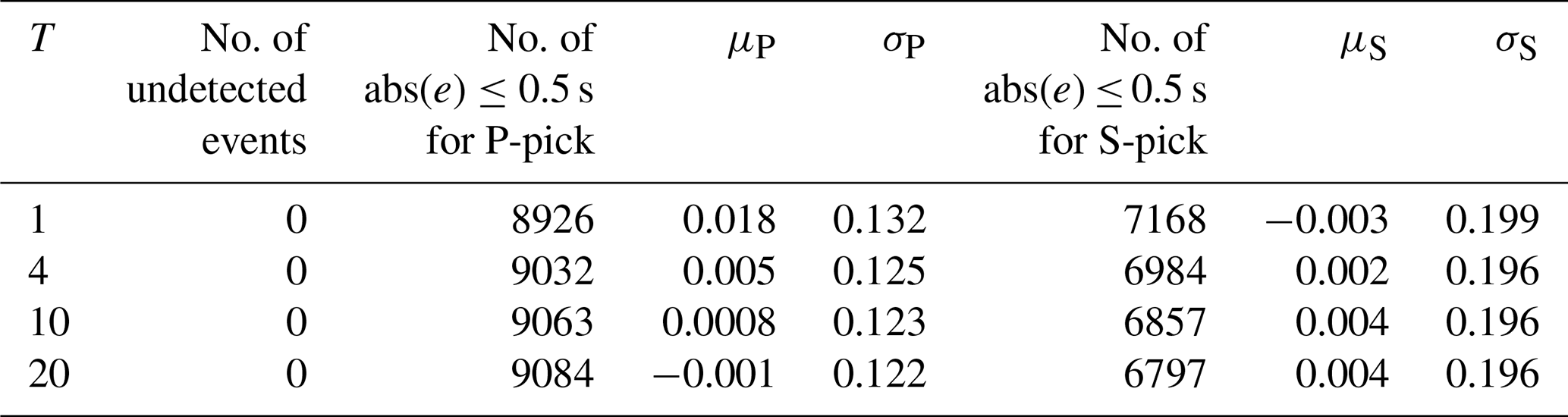
μP and σP are the mean and standard deviation of errors (ground truth − prediction) in seconds, respectively, for P-phase picking. μS and σS are the mean and standard deviation of errors (ground truth − prediction) in seconds, respectively, for S-phase picking.
Table A2Body-wave arrival-time evaluation using different shift numbers on the STEAD dataset.
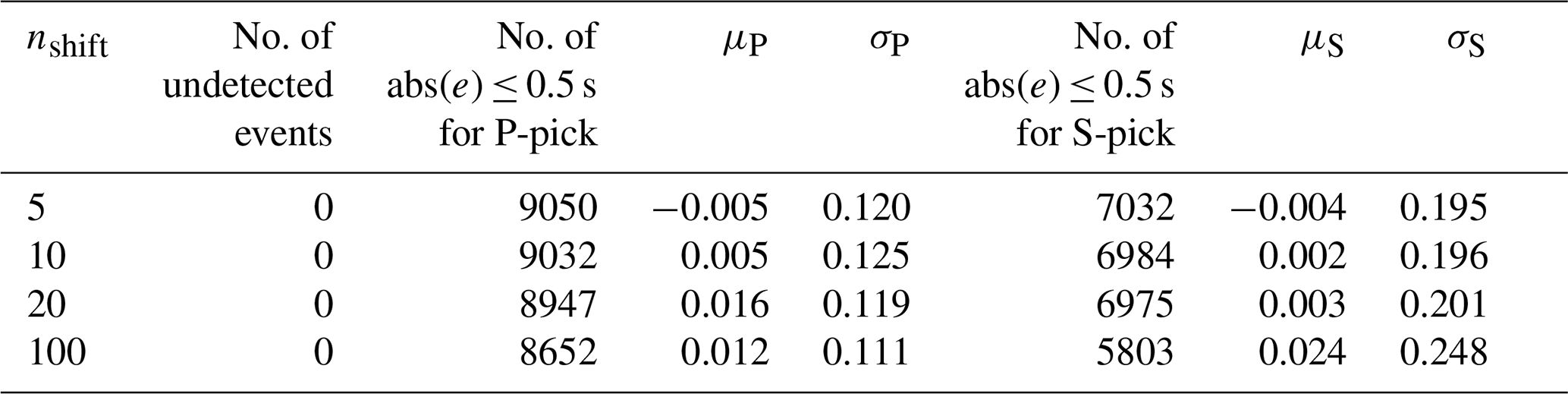
μP and σP are the mean and standard deviation of errors (ground truth − prediction) in seconds, respectively, for P-phase picking. μS and σS are the mean and standard deviation of errors (ground truth − prediction) in seconds, respectively, for S-phase picking.
Table B1Statistical results of magnitude estimation. Mag (MLv) and MagAv (MLv) are the individual magnitudes of each station and the magnitude average values from all stations, respectively, according to the KOERI-RETMC catalog (Bogazici University Kandilli Observatory and Earthquake Research Institute National Earthquake Monitoring Center, 2023). μmag and σmag are the mean and standard deviation of the magnitude calculated by CREIME for consecutive time windows for which the P-arrival probability calculated by DynaPicker exceeds the threshold of 0.7.
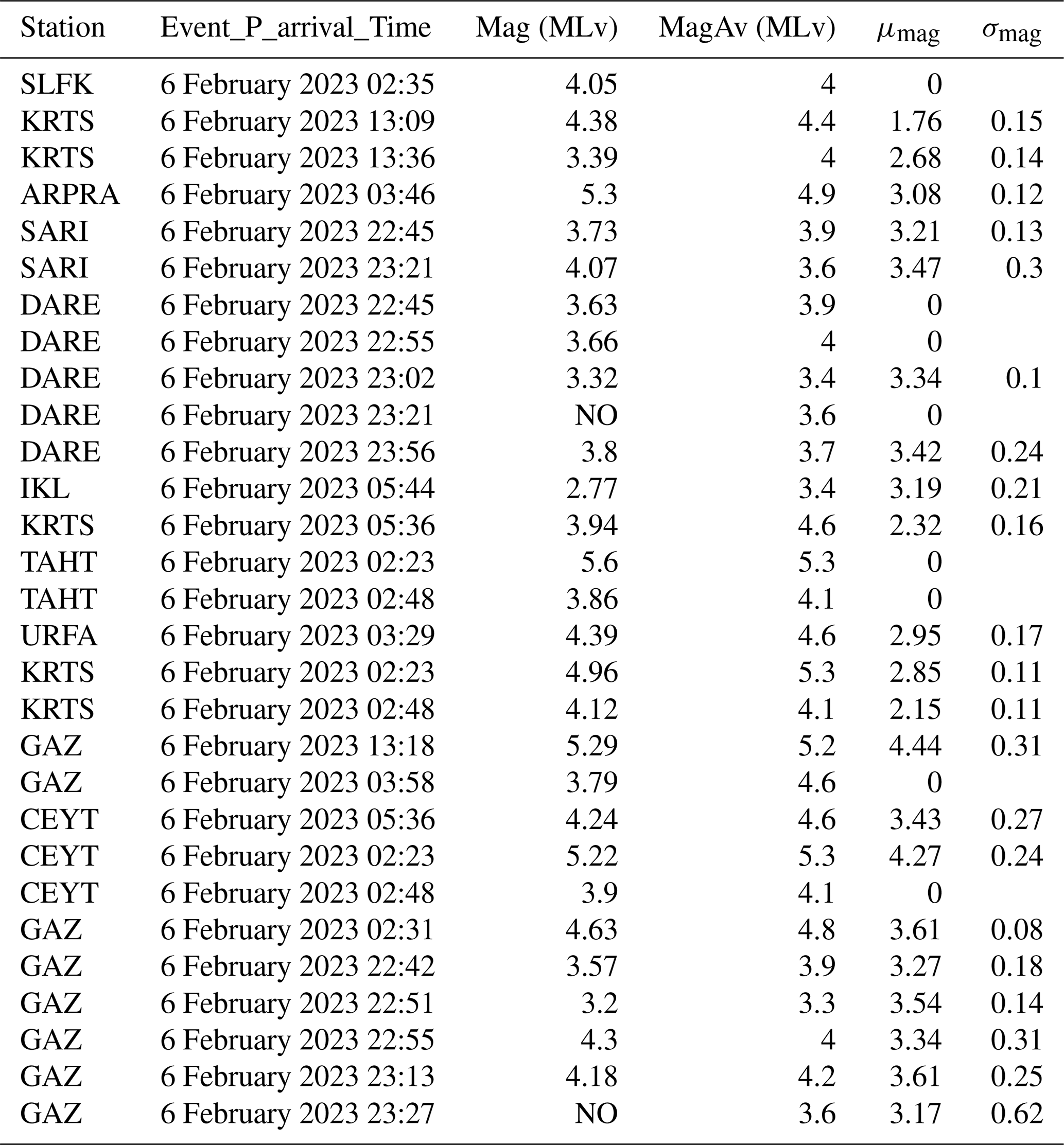
μmag and σmag are the mean and standard deviation of the estimated magnitude. Here, NO means there are magnitude data in the catalog.
The seismic dataset of the Southern California Earthquake Data Center used in this study can be accessed at https://scedc.caltech.edu/data/deeplearning.html (California Institute of Technology, 2023). The STEAD data can be downloaded from https://doi.org/10.1109/ACCESS.2019.2947848 (Mousavi, 2023), and the INSTANCE dataset is freely available at https://doi.org/10.13127/instance (Michelini et al., 2023). Details on how to download and use the Iquique dataset can be found in SeisBench (Woollam et al., 2022).
WL: conceptualization, methodology, software, writing – original draft, writing – review and editing. MC: writing – review and editing, visualization and analysis. JK: writing – review and editing, visualization. CQC: data analysis and validation. GR: writing – review and editing. NS: conceptualization, methodology, writing – review and editing
The contact author has declared that none of the authors has any competing interests.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
This work is supported by the “KI-Nachwuchswissenschaftlerinnen” – grant SAI 01IS20059 by the Bundesministerium für Bildung und Forschung – BMBF. Calculations were performed at the Frankfurt Institute for Advanced Studies GPU cluster, funded by BMBF for the project Seismologie und Artifizielle Intelligenz (SAI). We thank the authors of Seisbench (Woollam et al., 2022) for their help in using the saved model of EQTransformer (Mousavi et al., 2020) in the Pytorch version, and we also thank Omar M. Saad for his help in using the pre-trained model of CapsPhase (Saad and Chen, 2021). We also would like to thank Johannes Faber for his helpful discussion. We would also like to thank the two anonymous reviewers who helped to improve the manuscript.
This research has been supported by the Bundesministerium für Bildung und Forschung (grant no. SAI 01IS20059).
This open-access publication was funded by the Goethe University Frankfurt.
This paper was edited by Ulrike Werban and reviewed by two anonymous referees.
Agarap, A. F.: Deep learning using rectified linear units (relu), arXiv [preprint], arXiv:1803.08375, https://doi.org/10.48550/arXiv.1803.08375, 2018. a
Akazawa, T.: A technique for automatic detection of onset time of P-and S-phases in strong motion records, in: Proc. of the 13th World Conf. on Earthquake Engineering, vol. 786, p. 786, Vancouver, Canada, https://www.iitk.ac.in/nicee/wcee/article/13_786.pdf (last access: May 2023), 1–4 August 2004, Vancouver B.C., Canada, 2004. a, b
Allen, R. V.: Automatic earthquake recognition and timing from single traces, B. Seismol. Soc. Am., 68, 1521–1532, 1978. a
Bogazici University Kandilli Observatory and Earthquake Research Institute National Earthquake Monitoring Center: http://www.koeri.boun.edu.tr/sismo/2/latest-earthquakes/automatic-solutions/, last access: May 2023. a
California Institute of Technology (Caltech): Southern California Seismic Network, https://scedc.caltech.edu/data/deeplearning.html, last access: May 2023. a
Center, S. C. E. D.: Southern California Earthquake Data Center (2013), California Institute of Technology [data set], https://doi.org/10.7909/C3WD3xH1, 2013. a, b, c, d, e, f, g, h, i
Chakraborty, M., Rümpker, G., Stöcker, H., Li, W., Faber, J., Fenner, D., Zhou, K., and Srivastava, N.: Real Time Magnitude Classification of Earthquake Waveforms using Deep Learning, in: EGU General Assembly Conference Abstracts, EGU21–15941, https://doi.org/10.5194/egusphere-egu21-15941, 2021. a
Chakraborty, M., Cartaya, C. Q., Li, W., Faber, J., Rümpker, G., Stoecker, H., and Srivastava, N.: PolarCAP – A deep learning approach for first motion polarity classification of earthquake waveforms, Artificial Intelligence in Geosciences, 3, 46–52, 2022a. a
Chakraborty, M., Fenner, D., Li, W., Faber, J., Zhou, K., Ruempker, G., Stoecker, H., and Srivastava, N.: CREIME: A Convolutional Recurrent model for Earthquake Identification and Magnitude Estimation, J. Geophys. Res.-Sol. Ea., 127, e2022JB024595, https://doi.org/10.1029/2022JB024595, 2022b. a, b, c
Chakraborty, M., Li, W., Faber, J., Rümpker, G., Stoecker, H., and Srivastava, N.: A study on the effect of input data length on a deep-learning-based magnitude classifier, Solid Earth, 13, 1721–1729, https://doi.org/10.5194/se-13-1721-2022, 2022c. a
Chen, Y., Dai, X., Liu, M., Chen, D., Yuan, L., and Liu, Z.: Dynamic convolution: Attention over convolution kernels, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11030–11039, https://doi.org/10.1109/CVPR42600.2020.01104, 13–19 June, Seattle, WA, USA, 2020. a, b, c
Fenner, D., Rümpker, G., Li, W., Chakraborty, M., Faber, J., Köhler, J., Stöcker, H., and Srivastava, N.: Automated Seismo-Volcanic Event Detection Applied to Stromboli (Italy), Front. Earth Sci., 10, 267, https://doi.org/10.3389/feart.2022.809037, 2022. a
Goodfellow, I., Bengio, Y., and Courville, A.: Deep learning, MIT press, http://www.deeplearningbook.org (last access: May 2023), 2016. a
Han, Y., Huang, G., Song, S., Yang, L., Wang, H., and Wang, Y.: Dynamic neural networks: A survey, arXiv [preprint], arXiv:2102.04906, https://doi.org/10.1109/TPAMI.2021.3117837, 2021. a
Kandilli Observatory And Earthquake Research Institute, Boğaziçi University: Kandilli Observatory And Earthquake Research Institute (KOERI), https://doi.org/10.7914/SN/KO, 1971. a
Kingma, D. P. and Ba, J.: Adam: A method for stochastic optimization, arXiv [preprint], arXiv:1412.6980, https://doi.org/10.48550/arXiv.1412.6980, 2014. a
LeCun, Y., Bengio, Y., and Hinton, G.: Deep learning, Nature, 521, 436–444, 2015. a
Leonard, M. and Kennett, B.: Multi-component autoregressive techniques for the analysis of seismograms, Phys. Earth Planet. In., 113, 247–263, 1999. a
Li, W., Rümpker, G., Stöcker, H., Chakraborty, M., Fenner, D., Faber, J., Zhou, K., Steinheimer, J., and Srivastava, N.: MCA-Unet: Multi-class Attention-aware U-net for Seismic Phase Picking, in: EGU General Assembly Conference Abstracts, EGU21–15 841, https://doi.org/10.5194/egusphere-egu21-15841, 2021a. a
Li, W., Chakraborty, M., Fenner, D., Faber, J., Zhou, K., Ruempker, G., Stoecker, H., and Srivastava, N.: EPick: Attention-based Multi-scale UNet for Earthquake Detection and Seismic Phase Picking, Front. Earth Sci., 10, 2075, https://doi.org/10.3389/feart.2022.953007, 2022a. a, b
Li, W., Sha, Y., Zhou, K., Faber, J., Ruempker, G., Stoecker, H., and Srivastava, N.: A study on small magnitude seismic phase identification using 1D deep residual neural network, Artificial Intelligence in Geosciences, 3, 115–122, 2022b. a, b, c, d, e, f, g, h, i, j
Li, Y., Chen, Y., Dai, X., Liu, M., Chen, D., Yu, Y., Yuan, L., Liu, Z., Chen, M., and Vasconcelos, N.: Revisiting dynamic convolution via matrix decomposition, arXiv [preprint], arXiv:2103.08756, https://doi.org/10.48550/arXiv.2103.08756, 2021b. a, b, c, d, e, f, g, h, i, j
Michelini, A., Cianetti, S., Gaviano, S., Giunchi, C., Jozinović, D., and Lauciani, V.: INSTANCE – the Italian seismic dataset for machine learning, Earth Syst. Sci. Data, 13, 5509–5544, https://doi.org/10.5194/essd-13-5509-2021, 2021. a, b, c, d, e
Michelini, A., Cianetti, S., Gaviano, S., Giunchi, C., Jozinović, D., and Lauciani, V.: INSTANCE The Italian Seismic Dataset For Machine Learning, https://doi.org/10.13127/instance, last access: 2023. a
Mousavi, S. M., Sheng, Y., Zhu, W., and Beroza, G. C.: STanford EArthquake Dataset (STEAD): A global data set of seismic signals for AI, IEEE Access, 7, 179464–179476, 2019a. a, b, c, d, e, f, g
Mousavi, S. M., Zhu, W., Sheng, Y., and Beroza, G. C.: CRED: A deep residual network of convolutional and recurrent units for earthquake signal detection, Sci. Rep., 9, 1–14, 2019b. a
Mousavi, S. M., Ellsworth, W. L., Zhu, W., Chuang, L. Y., and Beroza, G. C.: Earthquake transformer – an attentive deep-learning model for simultaneous earthquake detection and phase picking, Nat. Commun., 11, 1–12, 2020. a, b, c, d, e
Mousavi, S. M., Sheng, Y., Zhu, W., and Beroza G. C.: STanford EArthquake Dataset (STEAD): A Global Data Set of Seismic Signals for AI, IEEE Access, https://doi.org/10.1109/ACCESS.2019.2947848, last access: 2023. a
Münchmeyer, J., Woollam, J., Rietbrock, A., Tilmann, F., Lange, D., Bornstein, T., Diehl, T., Giunchi, C., Haslinger, F., Jozinović, D., and Michelini, A.: Which picker fits my data? A quantitative evaluation of deep learning based seismic pickers, J. Geophys. Res.-Sol. Ea., 127, e2021JB023499, https://doi.org/10.1029/2021JB023499, 2022. a
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Köpf, A., Yang, E., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J. L., and Chintala, S.: Pytorch: An imperative style, high-performance deep learning library, Adv. Neur. In., 32, 8026–8037, https://dl.acm.org/doi/10.5555/3454287.3455008, 2019. a
Perol, T., Gharbi, M., and Denolle, M.: Convolutional neural network for earthquake detection and location, Science Advances, 4, e1700578, https://doi.org/10.1126/sciadv.1700578, 2018. a
Ross, Z. E., Meier, M.-A., Hauksson, E., and Heaton, T. H.: Generalized seismic phase detection with deep learning, B. Seismol. Soc. Am., 108, 2894–2901, 2018. a, b, c, d, e, f, g, h, i, j
Saad, O. M. and Chen, Y.: CapsPhase: Capsule Neural Network for Seismic Phase Classification and Picking, IEEE T. Geoscience Remote, 60, 5904311, https://doi.org/10.1109/TGRS.2021.3089929, 2021. a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y
Sabour, S., Frosst, N., and Hinton, G. E.: Dynamic routing between capsules, Adv. Neur. In., 30, 3859–3869, 2017. a
Simonyan, K. and Zisserman, A.: Very Deep Convolutional Networks for Large-Scale Image Recognition, in: International Conference on Learning Representations, https://doi.org/10.48550/arXiv.1409.1556, 2015. a
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., and Salakhutdinov, R.: Dropout: a simple way to prevent neural networks from overfitting, J. Mach. Learn. Res., 15, 1929–1958, 2014. a
Stehman, S. V.: Selecting and interpreting measures of thematic classification accuracy, Remote Sens. Environ., 62, 77–89, 1997. a
Stepnov, A., Chernykh, V., and Konovalov, A.: The Seismo-Performer: A Novel Machine Learning Approach for General and Efficient Seismic Phase Recognition from Local Earthquakes in Real Time, Sensors, 21, 6290, https://doi.org/10.3390/s21186290, 2021. a, b, c
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I.: Attention is all you need, Adv. Neur. In., 30, 6000–6010, 2017. a
Woollam, J., Rietbrock, A., Bueno, A., and De Angelis, S.: Convolutional neural network for seismic phase classification, performance demonstration over a local seismic network, Seismol. Res. Lett., 90, 491–502, 2019. a, b, c, d, e
Woollam, J., Münchmeyer, J., Tilmann, F., Rietbrock, A., Lange, D., Bornstein, T., Diehl, T., Giunchi, C., Haslinger, F., Jozinović, D., Michelini, A., Joachim Saul, J., and Soto, H.: SeisBench – A toolbox for machine learning in seismology, Seismol. Soc. Am., 93, 1695–1709, 2022. a, b, c, d, e
Yang, B., Bender, G., Le, Q. V., and Ngiam, J.: Condconv: Conditionally parameterized convolutions for efficient inference, Adv. Neur. In., 32, 1307–1318, https://doi.org/10.5555/3454287.3454404, 2019. a
Zelenin, E., Bachmanov, D., Garipova, S., Trifonov, V., and Kozhurin, A.: The Active Faults of Eurasia Database (AFEAD): the ontology and design behind the continental-scale dataset, Earth Syst. Sci. Data, 14, 4489–4503, https://doi.org/10.5194/essd-14-4489-2022, 2022. a
Zhu, W. and Beroza, G. C.: PhaseNet: a deep-neural-network-based seismic arrival-time picking method, Geophys. J. Int., 216, 261–273, 2019. a
It is important to mention that the pre-trained versions of GPD and CapsPhase have the softmax function T value, used for seismic phase classification, set to 1. Therefore, in this study, the temperature T is specifically set to 4 solely for the phase picking process.
For further information regarding the retraining of CapsPhase and GPD, and the alterations made to DynaPicker, please refer to the Discussion section.
- Abstract
- Introduction
- Methodology
- Data and labeling
- Evaluation metrics for seismic phase classification
- Experiments and results
- Discussion
- Conclusions
- Appendix A: Parameter investigation
- Appendix B: Magnitude estimation by combining DynaPicker and CREIME on the aftershock sequence of Turkey earthquake.
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Methodology
- Data and labeling
- Evaluation metrics for seismic phase classification
- Experiments and results
- Discussion
- Conclusions
- Appendix A: Parameter investigation
- Appendix B: Magnitude estimation by combining DynaPicker and CREIME on the aftershock sequence of Turkey earthquake.
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References