the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 10 Sep 2019
| 10 Sep 2019
Modeling active fault systems and seismic events by using a fiber bundle model – example case: the Northridge aftershock sequence
Marisol Monterrubio-Velasco
F. Ramón Zúñiga
José Carlos Carrasco-Jiménez
Víctor Márquez-Ramírez
Josep de la Puente
Earthquake aftershocks display spatiotemporal correlations arising from their self-organized critical behavior. Dynamic deterministic modeling of aftershock series is challenging to carry out due to both the physical complexity and uncertainties related to the different parameters which govern the system. Nevertheless, numerical simulations with the help of stochastic models such as the fiber bundle model (FBM) allow the use of an analog of the physical model that produces a statistical behavior with many similarities to real series. FBMs are simple discrete element models that can be characterized by using few parameters. In this work, the aim is to present a new model based on FBM that includes geometrical characteristics of fault systems. In our model, the faults are not described with typical geometric measures such as dip, strike, and slip, but they are incorporated as weak regions in the model domain that could increase the likelihood to generate earthquakes. In order to analyze the sensitivity of the model to input parameters, a parametric study is carried out. Our analysis focuses on aftershock statistics in space, time, and magnitude domains. Moreover, we analyzed the synthetic aftershock sequences properties assuming initial load configurations and suitable conditions to propagate the rupture. As an example case, we have modeled a set of real active faults related to the Northridge, California, earthquake sequence. We compare the simulation results to statistical characteristics from the Northridge sequence determining which range of parameters in our FBM version reproduces the main features observed in real aftershock series. From the results obtained, we observe that two parameters related to the initial load configuration are determinant in obtaining realistic seismicity characteristics: (1) parameter P, which represents the initial probability order, and (2) parameter π, which is the percentage of load distributed to the neighboring cells. The results show that in order to reproduce statistical characteristics of the real sequence, larger πfrac values () and very low values of P () are needed. This implies the important corollary that a very small departure from an initial random load configuration (computed by P), and also a large difference between the load transfer from on-fault segments than by off-faults (computed by πfrac), is required to initiate a rupture sequence which conforms to observed statistical properties such as the Gutenberg–Richter law, Omori law, and fractal dimension.
- Article
(10885 KB) - Full-text XML
- BibTeX
- EndNote





Most earthquakes occur when adjacent blocks move along fractures in the Earth's crust, as a consequence of stress build-up arising from the regional strain and the stress change caused by a preceding earthquake or by the tectonic stress accumulation (Stein et al., 1994). These fractures, or faults, are discontinuous geological features consisting of a number of discrete segments (Segall and Pollard, 1980), which can be up to hundreds of kilometers in total length. Faults are the weakest parts of the crust and thus are more likely to release accumulated stresses, by means of slipping, than non-fractured crust. Earthquakes may occur many times on the same fault over millions of years. Known active faults have ruptured several times in the last 120 000 years and are considered likely to move again (Wallace, 1981). It has been observed that earthquakes are strongly correlated in space around the active fault systems (Kroll, 2012).
Fault systems have a statistical self-similar structure over a wide range of scales (Kagan and Knopoff, 1980; Sadovskiy et al., 1984; Hirata and Imoto, 1991) which can be described by means of fractal geometry, as introduced by Mandelbrot and Pignoni (1983). Geometrical fractal structures such as faults arise from self-organized criticality (SOC) phenomena over large temporal periods (Bak and Creutz, 1994).
Moreover, earthquakes follow power statistical laws for their observed scaling properties such as the Gutenberg–Richter (GR) distribution (Gutenberg and Richter, 1942; Scholz, 2002), the modified Omori (MO) law, (Omori, 1894; Godano et al., 1996; Hirata and Imoto, 1991), or the fractal dimension of their spatial distribution (Turcotte, 1997; Roy and Ram, 2006).
SOC systems have been studied as a means to explain seismicity by several authors (Barriere and Turcotte, 1994; Scholz, 1991). In particular, models based on cellular automata have been used to describe SOC behavior in earthquake series (Aki, 1965; Barriere and Turcotte, 1994; Castellaro and Mulargia, 2001; Georgoudas et al., 2007; Adamatzky and Martínez, 2016). The fiber bundle model (FBM), a model based on cellular automata (Peirce, 1926; Daniels, 1945; Coleman, 1956), provides a conceptual and numerical description of the rupture process in heterogeneous media (Kun et al., 2006b). In this article, we present a model that improves over the base model presented in Monterrubio-Velasco et al. (2017) by projecting the geometrical fault systems in a FBM algorithm. We developed a novel and powerful simulation model with simple and straightforward input parameters that is capable of providing simulation scenarios that are statistically consistent with real cases. The model circumvents the high complexity related to the derivation of deterministic models of by including faults as an abstraction that try to explain weaker regions that are more likely to generate earthquakes. In this version of the model, the faults are represented as a projection on the surface as a 2-D approximation. The extension to 3-D is being considered for a later phase of the study. We test the FBM's ability to capture the statistics coming from empirical laws (i.e., the GR law, the fractal capacity dimension, the MO law, and the Hurst exponent) by means of a parametric study. As a case study, we consider the Northridge aftershock sequence (17 January 1994, MW=6.7) along with the geometry of its fault system. The statistical characteristics from the Northridge aftershock sequence are compared with the statistics obtained in synthetic catalogs generated with our FBM. Even though we focus on one aftershock case, the applicability of our model can be extended to analyze other aftershock sequences using particular fault system as input configuration. For example, in Monterrubio-Velasco et al. (2018), this model was applied to classify, via machine learning algorithms, three different aftershock sequences. Lastly, we study the event productivity as function of on-fault (or weakling areas) and off-fault parameters.
This section gives a general description of the fiber bundle model and the statistical relations used in this work.
2.1 Fiber bundle model: general description
The basic components necessary to construct an FBM are (Andersen et al., 1997; Phoenix and Beyerlein, 2000; Pradhan and Chakrabarti, 2003; Sornette, 1989; Kloster et al., 1997):
-
Defining a discrete set of cells located in a regular (n-dimensional) lattice. For our purpose, this lattice will be two-dimensional, representing the geographical study area in an azimuthal view.
-
Assigning a probability distribution function for the inner properties of each cell. This failure law will define the probability distribution function of the stress (in the static case) or the probability distribution function of the rupture time (in the dynamic version) (Hansen et al., 2015).
-
Establishing the load-sharing rule. This component is crucial in a FBM since the model shows a fundamental change depending on the manner of the load transfer after a cell fail (Pradhan et al., 2010). The most used sharing rules are the equal or global load sharing (Turcotte et al., 2003) and the local sharing rule (LLS). This last sharing rule favors the stress concentrations and promotes nearest neighbors to reach a critical rupture state.
FBM was developed in two versions that simulate material rupture by different effects: (1) the static version in which the fiber strength is time independent (Vázquez-Prada et al., 1999; Kun et al., 2006a; Pradhan et al., 2010), and (2) the dynamic version where the study of the material rupture is a time-dependent process, such as stress rupture, creep rupture, static fatigue, or delayed rupture (Coleman, 1956; Moral et al., 2001b). In this research work, we will use a dynamic FBM with LLS in the probabilistic formulation developed in Moreno et al. (2001).
Probabilistic FBM
According to laboratory studies, the Weibull distribution describes the hazard rate (κ) on materials subjected to a constant load or stress, σ (Coleman, 1956; Moreno et al., 2001):
where ν0 is the hazard rate under stress σ0, and the ρ exponent is the Weibull index defined in the range (Yewande et al., 2003; Kun et al., 2006a; Nanjo and Turcotte, 2005). In the present work, we use a dimensionless representation of quantities, so that we can use normalized stresses and Eq. (1) can be written as κ(σ)=σρ, following Moreno et al. (2001) and Monterrubio-Velasco et al. (2017).
Gómez et al. (1998) introduced a probabilistic approach as an alternative formulation to the dynamic FBM which we follow here.
The FBM model simulation starts by discretizing a hypothetical surface in a bi-dimensional array (Nx×Ny). At the first step, the load of the cells in the bundle is assigned following a uniform distribution , and . The notation U[0,1) is a mathematical form to represents a uniform distribution with values in the range equal to or greater than 0 and lower than 1. This assumption simulates an initial heterogeneity in the load cell properties. The hazard rate assigned at each cell is computed using Eq. (1) (Moreno et al., 1999; Pradhan et al., 2010). Furthermore, a rupture probability, F(x,y), is computed for each individual element or cell, and at each step. This value is load dependent and is defined by
where δ is the time interval (or inter-event time) until the next rupture occurs, valid for any load-sharing rule (Moral et al., 2001a), computed as (Moreno et al., 2001; Moral et al., 2001a)
From Eq. (3), δ is a dimensionless quantity since σ(x,y) and ρ are dimensionless.
The time of occurrence or cumulative time T(k) is defined as
where , being kmax the maximum number of steps. Our model uses Eqs. (2), (3), and (4) to compute the rupture probability and the inter-event time.
2.2 Previous aftershock models
In our previous work, we developed a FBM version to simulate spatial and magnitude aftershock patterns. Following the general assumptions proposed in Correig et al. (1997), we modified it in order to define a computational domain that describes a particular geographical area. Moreover, the initial load values are ordered according to a probability value P. P=0 represents a random spatial distribution of initial loads (heterogeneous), and P=1 implies a homogeneous distribution in agreement with a proxy of Coulomb stress changes produced by a main event in the center of the computational domain Ω (Monterrubio-Velasco et al., 2017).
A local load-sharing rule including the eight nearest neighbors, and a threshold load (σth≡1) are established a priori. When the load in a cell exceeds this threshold load, a critical point is reached and a imminent rupture occurs (called avalanches). If more than one cell exceeds σth, the cell to fail is that which exhibits the maximum load. The rupture algorithm is sequential, since at each time step one cell has to fail. The inter-event time (δ) must be updated at each discrete step as described in Eq. (3). After a cell fails, they distribute its respective percentage of load () to its eight neighbors. Perpendicular neighbors will receive the largest amount of load (), while diagonal neighbors get a load of . The different weights were chosen considering what is expected for the maximum shear stress directions with respect to the main stress orientation that gives rise to both synthetic and antithetic faulting (e.g., Stein et al., 1994). In Monterrubio-Velasco et al. (2017), a large number of numerical experiments were carried out to define the appropriate values of these quantities. Varying the weights results in slight changes but as long as the main directional properties in weight are preserved the output does not change significantly.
2.3 Statistical and fractal relations
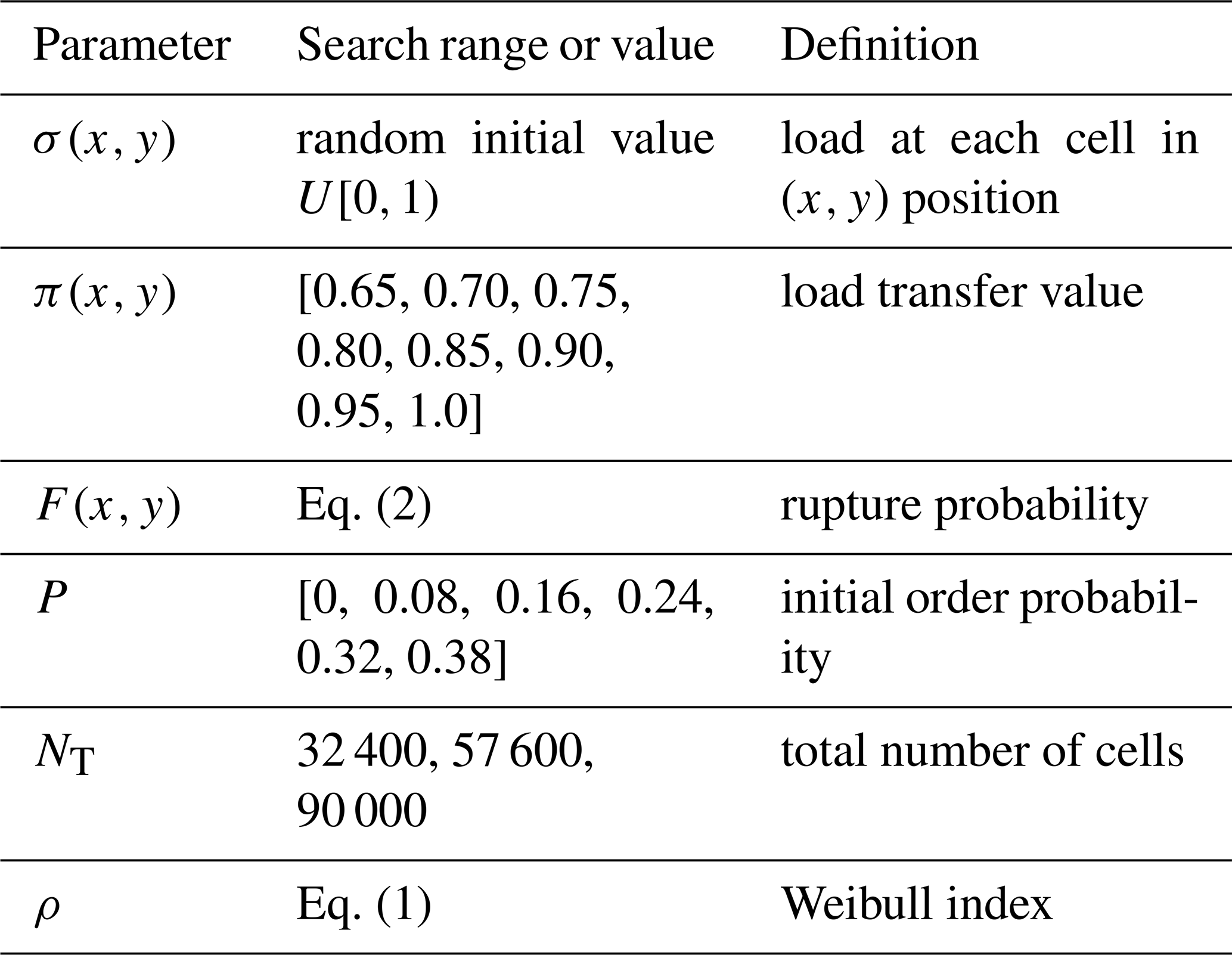
In order to quantify the resemblance between synthetic catalogs and real seismic catalogs, we use statistical measures which are relevant for evaluating the SOC behavior. These measures are represented by power laws in magnitude (GR law), time (MO law), and space (e.g., fractal dimension). In Appendix A1, we introduce these relations, describing their applicability, as well as the interpretation and the methods of quantification. Table 1 summarizes the characteristics, abbreviations, and usefulness of the empirical relations used in this work.
Table 1Empirical relations, interpretation, and main parameters.

3.1 Extending the model
In our previous work (Monterrubio-Velasco et al., 2017), we did not incorporate the information of the fault geometry which is a fundamental property to describe a particular tectonic region. Therefore, the main contribution of this research work is extending the model by the addition of the fault system geometry by prescribing parameters that quantify “weakness” properties, i.e., the capacity to produce load concentrations that generate a rupture. In contrast to the classical definition that uses measures such as dip, strike, and slip, here, the faults are considered the weakest parts of the Earth's crust. The parameter π quantifies the load transfer and it controls the amount of load distributed from a failed cell to its neighbors. Since the seismic rupture is not conservative, the parameter π(x,y) defines the percentage of load lost at each discrete step. The output of the model is a synthetic catalog with statistical properties that change depending on the input parameters.
Algorithm
In the Appendix, three pseudo-codes are included to describe the model algorithm. Our model is coded in Julia language (Bezanson et al., 2017) for the sequential version and in Python language for the paralleled version of the loops.
-
The initial conditions are as follows:
In this work, and as a first attempt, we simplified the real 3-D domain by choosing a bi-dimensional surface to represent the epicentral distribution. Moreover, we assume that considering that the seismicity of southern California is shallow and mostly restricted to the planar strike-slip faults, the two-dimensional approach can be used as a simplification. Therefore, the 2-D Cartesian grid is a rectangular domain Ω of square cells. The domain is a planar representation of the study area for which we define three values at each cell in and that assign their properties:
-
σ(x,y): a discrete value of load where the initial load distribution is taken from a uniform distribution function with values in the range [0,1).
-
π(x,y): a load-transfer value that defines the percentage of the load distributed to the neighbors after a cell fails. Since the fault geometry is an abstraction that simulates weaker regions in the model domain, the values of π(x,y) that define the percentage of load distributed after a cell fails have either a background value (πback) or a fault value (πfrac).
-
F(x,y): a rupture probability described in Eq. (2).
-
The Weibull index, ρ (Eq. 1): Monterrubio-Velasco (2013) carried out an exhaustive study to analyze the effect of ρ on the generated time series (Eq. 3). It was found that an appropriate value of this parameter must fall within the range .
-
P, the heterogeneity of the initial load distribution: this parameter has a global influence on the final scenario but we have used the best configuration as tested in Monterrubio-Velasco et al. (2017).
No external load is received after the initial load assignation, so that our model describes the relaxation process after a mainshock. Therefore, we do not discuss or simulate the mainshock or foreshocks. The load increase in a cell is due to internal load transfer processes. In a companion study (Monterrubio-Velasco et al., 2019), we present the TREMOL v0.1 code which studies the case of asperities. That model was developed as a mainshock simulator based on the FBM to analyze the case of Mexican subduction earthquakes. A version of our model that includes the effect of tectonic loading is still in progress.
-
-
The rupture conditions are as follows:
In this work, we choose the values proposed in Monterrubio-Velasco et al. (2017, 2019) in order to reduce the degrees of freedom. The only two parameters that change during the execution of the model are σ(x,y) and F(x,y). Throughout the iterations of the simulation, we identify two possible outcomes: normal events, i.e., minor or background ruptures, and avalanches, i.e., a collection of spatiotemporally clustered events that result in large rupture (Monterrubio-Velasco et al., 2017). We remark that, in the present work, avalanches are actual secondary ruptures, whereas normal events are minor events of low magnitude that produce the rupture of a single cell. The consecutive rupture of avalanches events will produce a rupture cluster with a size determined by their area in (cell) units S(NA).
-
The completion of a simulation is as follows:
A FBM simulation is terminated when any cell in the system is unable to exceed the threshold σth. We have empirically determined that the total number of steps kmax when this situation occurs is typically kmax . Beyond this value, the system no longer generates loads that overpass σth. Hence, we take this value as a terminal condition in our simulations. After the simulation is completed, we obtain a synthetic seismic catalog which includes the number of simulated earthquakes (NA) with their corresponding area S(NA) (number of events that produces a single rupture), occurrence time tA (Eq. 3), and their spatial location (x,y). In Sect. 3.2, we discuss how the avalanche size S(NA) can be converted into magnitude. It should be noted that two realizations with identical parameters result in different seismic catalogs due to the random component in the initial load. A detail procedure is explained in the pseudo-codes provided in Appendix A2.
3.2 Experimental procedure
The discrete planar faults of a particular region are modeled by using an image of the real fault system. This image is mapped in the domain Ω (see the example in Fig. 1). A parametric study is employed to determine the best range of values to produce synthetic catalogs with appropriate statistical characteristics. In this work, we use the following parameters: ρ=30, σth=1, , and . We also fix a background πback=0.65 value for all non-faulted cells and assume a square grid, with same lateral size on the x axis and y axis, i.e., . These values are considered from the results obtained in Monterrubio-Velasco et al. (2017). The reasons to choose these values are summarized as follows:
-
produces features observed in real aftershock time series (Monterrubio-Velasco, 2013; Monterrubio et al., 2015).
-
σth=1 is the upper bound of the uniform distribution and appears as a natural threshold.
-
In Monterrubio-Velasco (2013), Monterrubio et al. (2015), and Monterrubio-Velasco et al. (2017), a range of was determined experimentally to produce ruptures that mimic features of real catalogs without considering any difference between regions (i.e., no difference between faulting and non-faulting regions). We considered πback=0.65 as a mid-range value to be assigned to background cells.
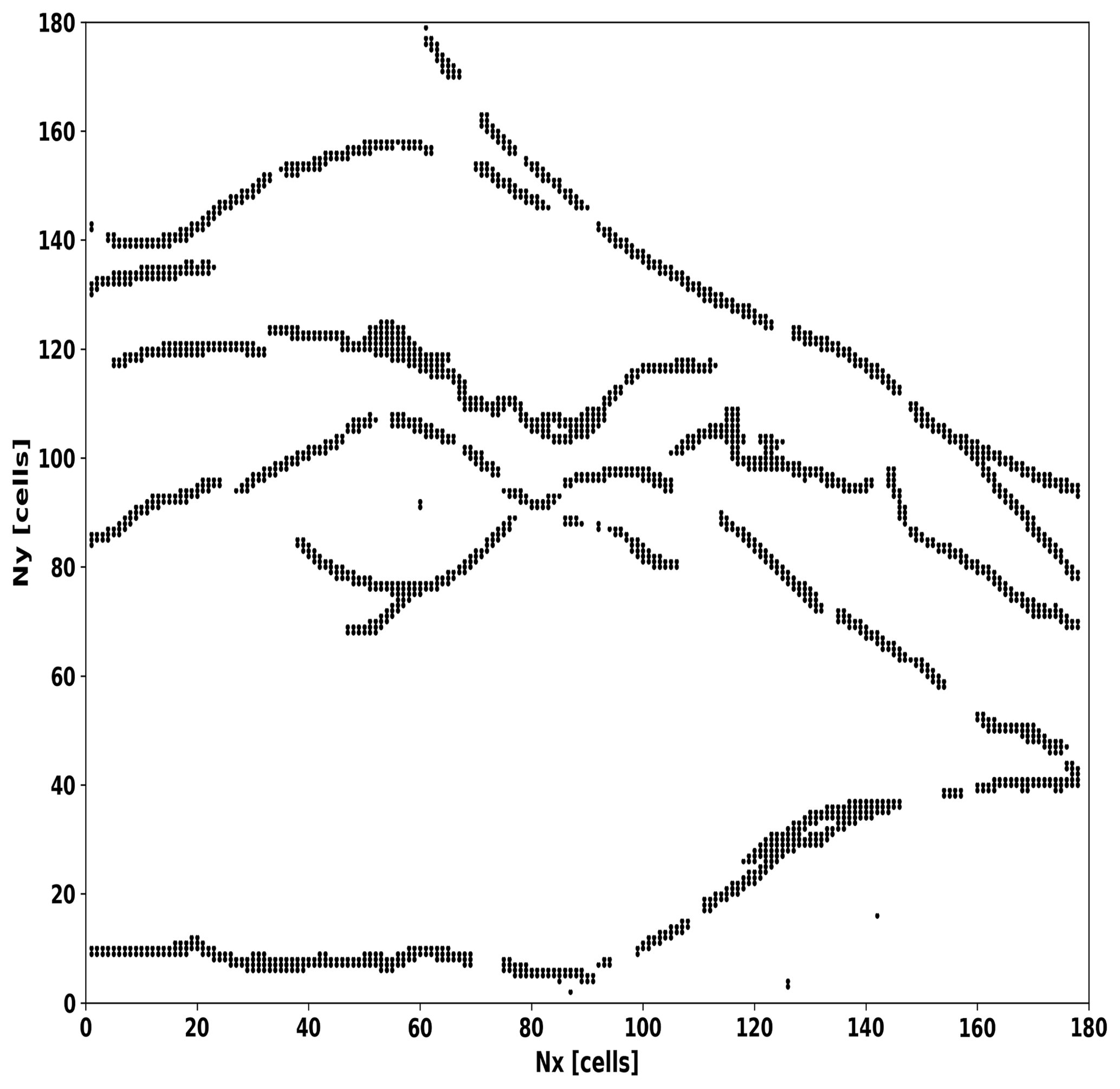
Figure 1Map (azimuthal view) of the Northridge fault system. It is digitalized to include in our computing domain where each pixel of the map corresponds to a cell (x,y) in our array.
The map of faults has a real physical size in km2. So, after executing the Algorithm 1 in Sect. A2.1 (Appendix A2), in the post-processing analysis, we assign an area at each cell in km2, namely Acell. To compute the avalanche area S(NA) in km2, we use the relation
for . We computed an equivalent magnitude using the scale magnitude–area relation proposed by Hanks and Bakun (2008) in Eq. (6).
where Aj, for is the rupture area expressed in km2 and MW is the moment magnitude. This relation is specific for events in a crustal-plate-boundary tectonic regime (Stirling and Goded, 2012).
Careful attention has been given to minimum magnitudes which depend on size of the cell Acell, i.e., are proportional to N−2 Monterrubio-Velasco et al. (2018). In order to make results comparable for different grid sizes, we filter out events rupturing less than a minimum amount of cells for the finer grids. This is done because we want to show the influence of different grid sizes over the statistical results, and we want to compare our results with real cases where the smallest magnitudes are not resolved by the seismograph networks.
We are left with three freely varying parameters for our study. Based on previous results, we use Nx = [180, 240, 300] cells, πfrac = [0.6, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9, 0.95, 1.0], and P = [0.0, 0.08, 0.16, 0.24, 0.32, 0.38] (Monterrubio-Velasco et al., 2018). This results in 162 samples in the parametric space.
The epicentral location of the simulated aftershocks is the position of the first avalanche event ((Ex(j),Ey(j))) in the cluster.
We define Δ(r) as series of the Euclidean distance between two consecutive epicenters and τ(t) the inter-event time series corresponding to two consecutive avalanches (see Eq. 4).
Table 2 defines the model parameters and provides optimal search ranges.
In order to validate and compare our synthetic seismic catalogs with real seismicity, we modeled as an example case the fault system geometry and the seismic properties of the Northridge aftershock sequence (Fig. 2). The Northridge mainshock (MW=6.7) occurred on 17 January 1994 at 04:31 UTC. The earthquake shook the San Fernando Valley, which is 31 km northwest of Los Angeles, near the community of Northridge. This earthquake is the largest recorded in the Los Angeles metropolitan area in the last century. The depth of the hypocenter was 18±1 km. The seismic moment, Mo, was estimated at 1.58×1023 N m, with a stress drop of 27 MPa (Thio and Kanamori, 1996). The mainshock occurred due to the rupture of a previously unrecognized blind reverse fault with a moderate southward dip (Savage and Svarc, 2010; Scientists of the U.S. Geological Survey, 1994). The Northridge mainshock occurred at a fault belonging partly to a large fault system in the transverse ranges. This fault system is under compression in the NNW direction related to the “big bend” of the San Andreas Fault (Norris and Webb, 1990; Hauksson et al., 1995). The Northridge earthquake was followed by a sequence of aftershocks, between 17 January and 30 September 1999, including eight aftershocks of magnitude MW≥5 and 48 of . We computed the statistical parameters of the aftershocks using the data recorded by the Southern California Seismic Network. We consider the aftershock time period from the mainshock (17 January 1994 at 04:31 UTC) until 1 year later (17 January 1995). In space, we consider events that occur in a square area of 0.6∘ × 0.6∘ taking as center the mainshock epicenter (Turcotte, 1997) In Fig. 2, we show the spatial representation of the faults analyzed in this work, and the seismicity of magnitude larger than 2.0 during 1981–2006. We also assumed that the faulting area is the same, independently of the model domain size Ω. However, the number of cells modify the size of each cell, resulting in 0.077, 0.043, and 0.027 km2 for Nx = [180, 240, 300] cells, respectively.
Table 3Statistical parameters of the real catalog of Northridge aftershocks using different threshold magnitudes (Mmin).
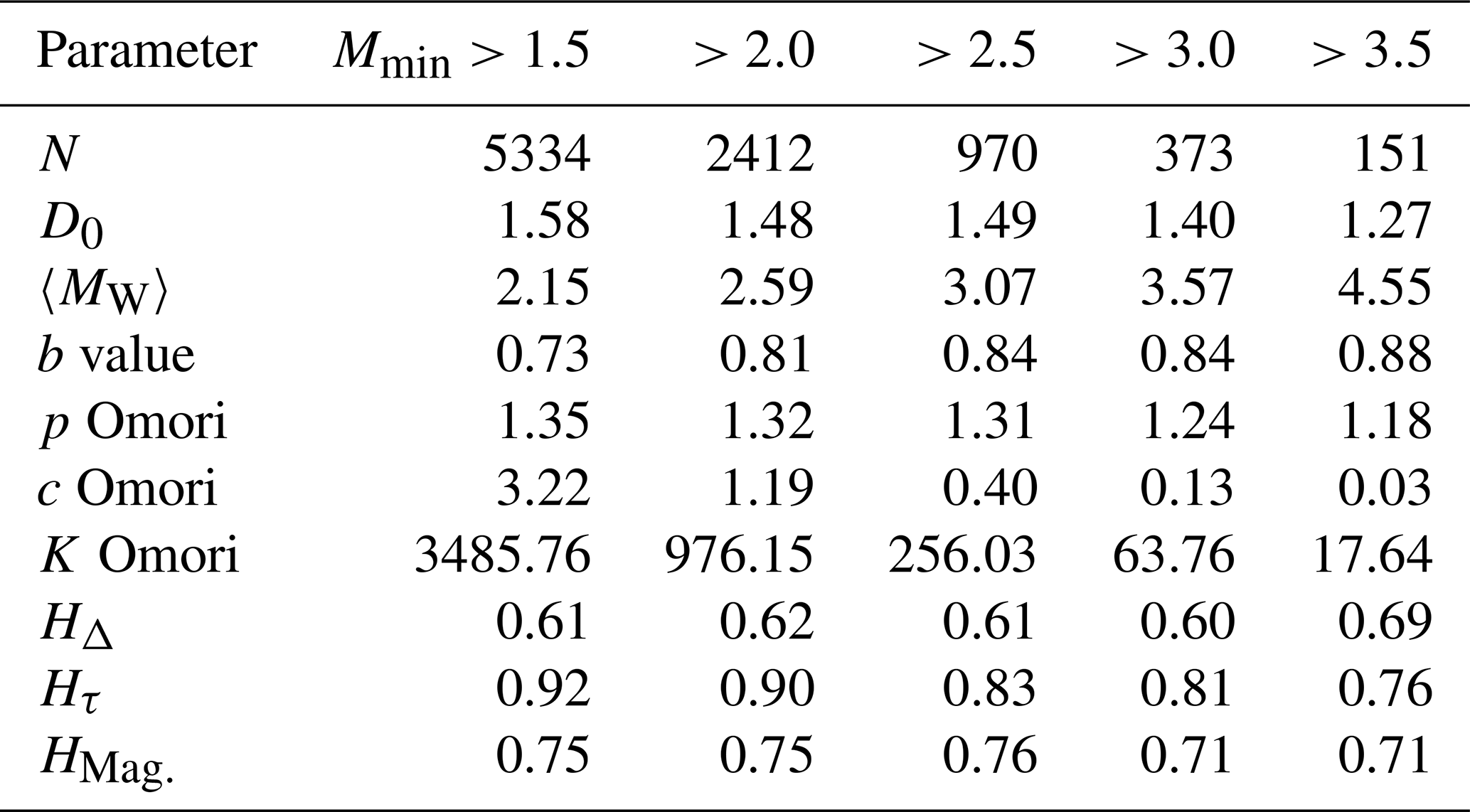
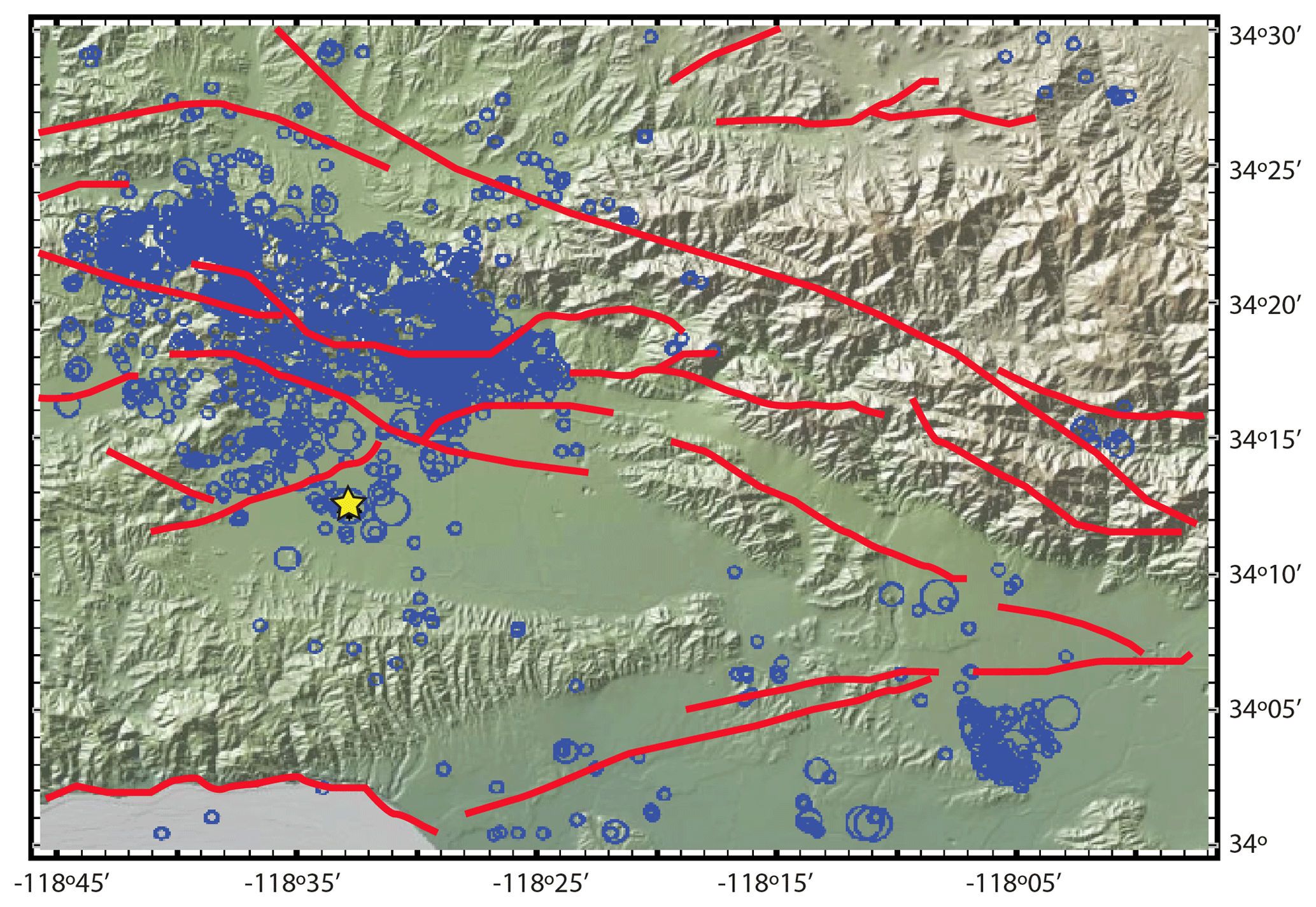
Figure 2Map that includes the seismicity of magnitude larger than 2.0 during 1981–2006. The yellow star indicates the Northridge epicenter (MW 6.7, 1994). Red lines depict the faults of this region considering an approximated area of 0.6∘ × 0.6∘. Blue circles indicate aftershock locations and the size of their magnitude.
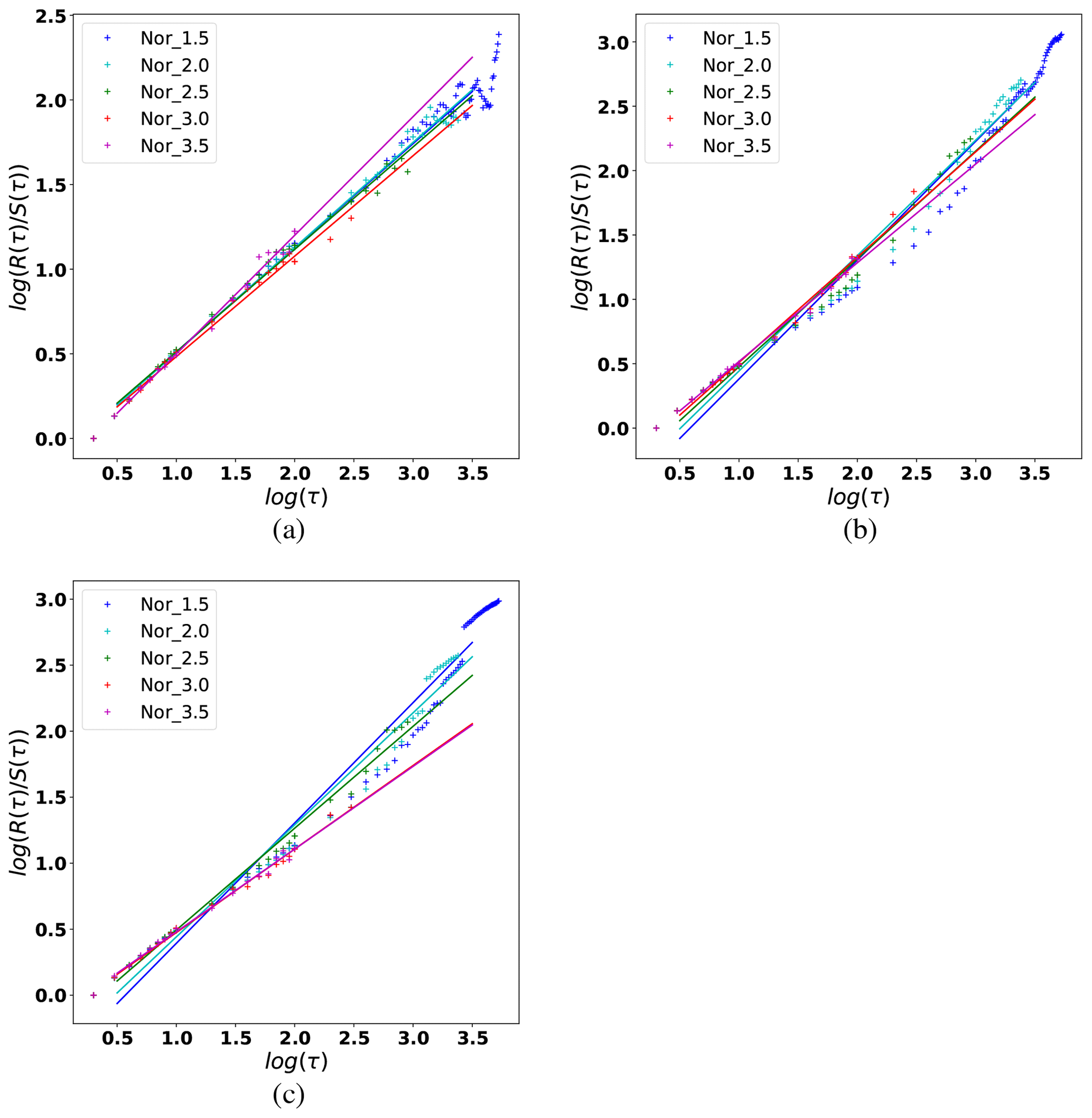
In Table 3, we show the statistical parameters for the Northridge sequence computed for different threshold magnitudes from Mmin=1.5 to Mmin=3.5. These values will be used as a reference to determine the sets of FBM parameters that best reproduce the Northridge statistics. Figures 3 and 4 show the fitting of the GR law, MO law, and Hurst exponents (HΔ, Hτ, and HMag) for different minimum magnitudes (Mmin>1.5, >2.0, >2.5, >3.0, and >3.5). We note that Wiemer and Wyss (2000) calculated the minimum magnitude of completeness in the Los Angeles area as Mc≈1.5.

Figure 3Fitting of the (a) GR law and (b) MO law to the Northridge aftershocks (NOR) considering different minimum magnitudes: Mmin, 1.5 (dark blue markers), 2.0 (turquoise), 2.5 (green), 3.0 (red), and 3.5 (pink), respectively.
We divide the results and their analysis in three domains:
-
space: fractal capacity dimension, D0, for the epicentral distribution of synthetic earthquakes, and Hurst exponent for epicentral distance between consecutive synthetic earthquakes, H(Δ);
-
magnitude: b value, maximum avalanche size maxS(NA), mean magnitude, and maximum magnitude; and
-
time: inter-event times H(τ) and MO parameters (p, c, K).
5.1 Parametric analysis over the synthetic series
For each parameter, we list its observed properties to facilitate the reading. We are analyzing simultaneously three parameters (the size of the domain N measured in cells units, the initial order configuration P, and the percentage of transfer load in a fault-on cell πfrac). However, it is worth noting that they are coupled between them. Then, we analyze how these three parameters are modifying the statistical and the fractal properties of synthetic catalogs.
5.1.1 Fractal dimensions of synthetic catalogs
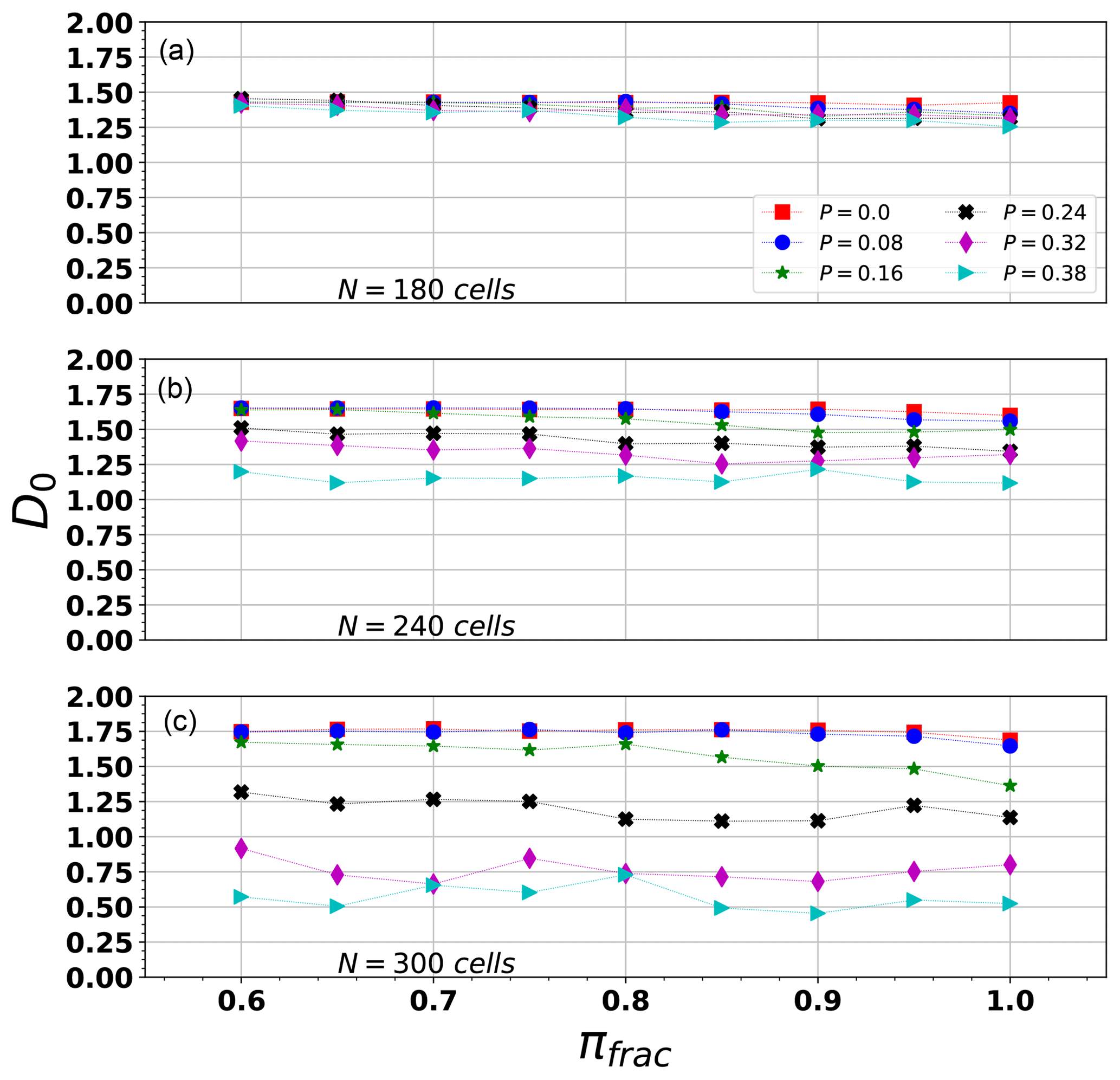
The first analysis is related to the fractal capacity dimension, D0 (Sect. A1.1), shown in Fig. 5.
-
As N increases, D0 becomes more sensitive to P (where P is the initial load values ordered according to a probability value), because the larger the area, the more abundant and scattered the events, and the effect of P over the simulated events increases. The effect of an increase in P is a reduction of D0. On the other hand, as P tends to zero, the events are more scattered because randomness in the initial load causes sparsity in the event distribution.
-
πfrac does not seem to have a large impact in D0 across our experimental range.
-
For P≤0.16 and πfrac>0.9 (for all N values), our FBM simulations yield a D0 compatible with that computed for the Northridge series with a Mmin≈2 (Table 3).
5.1.2 The b value, mean, and maximum magnitude of synthetic catalogs
The b value is clearly influenced by all three parameters (N, P, and πfrac), as is shown in Fig. 6.
-
The smallest array of N=180 cells tends to produce similar b values, independently of P and πfrac. On the other hand, as N increases, the b value is more sensitive to P and πfrac.
-
For values of N=240 and 300 cells, the b value shows a clear dependency on πfrac. In these finer grids (N=240), we consider an initial random load distribution P=0, we observe that the synthetic b approaches b values computed for the Northridge sequence, if πfrac>0.90. This last observation is important to justify the influence of include fractures regions in our model. Because πfrac>0.90, it indicates a clear “non-conservative” properties in the fault-on cells, and under this assumptions b value is closer to the expected value computed for Northridge.
The difference in the b values as a function of N might be due to two possible causes:
-
the number of events included in the statistical fit and
-
the size of the earthquake-simulated avalanches, S(NA). In fact, related to this observation in Fig. 7, we observe that as P increases, the maximum magnitude also increases, also modifying the frequency–magnitude distribution and the b value.
As an example, Fig. 8 shows the frequency–magnitude distribution for P = [0, 0.08, 0.16, 0.24, 0.32, 0.38], πfrac=0.9, πfrac=0.65, and N=300. We observe that as P increases, the productivity of intermediate size events decreases, and the maximum magnitude increases. Large P values imply that the probability to find cells with large loads clustered in the middle increases (Monterrubio-Velasco et al., 2017). So, in this condition, it is more likely to generate larger earthquakes. This behavior is similar to that observed in the characteristic earthquake distribution (Wesnousky, 1994).
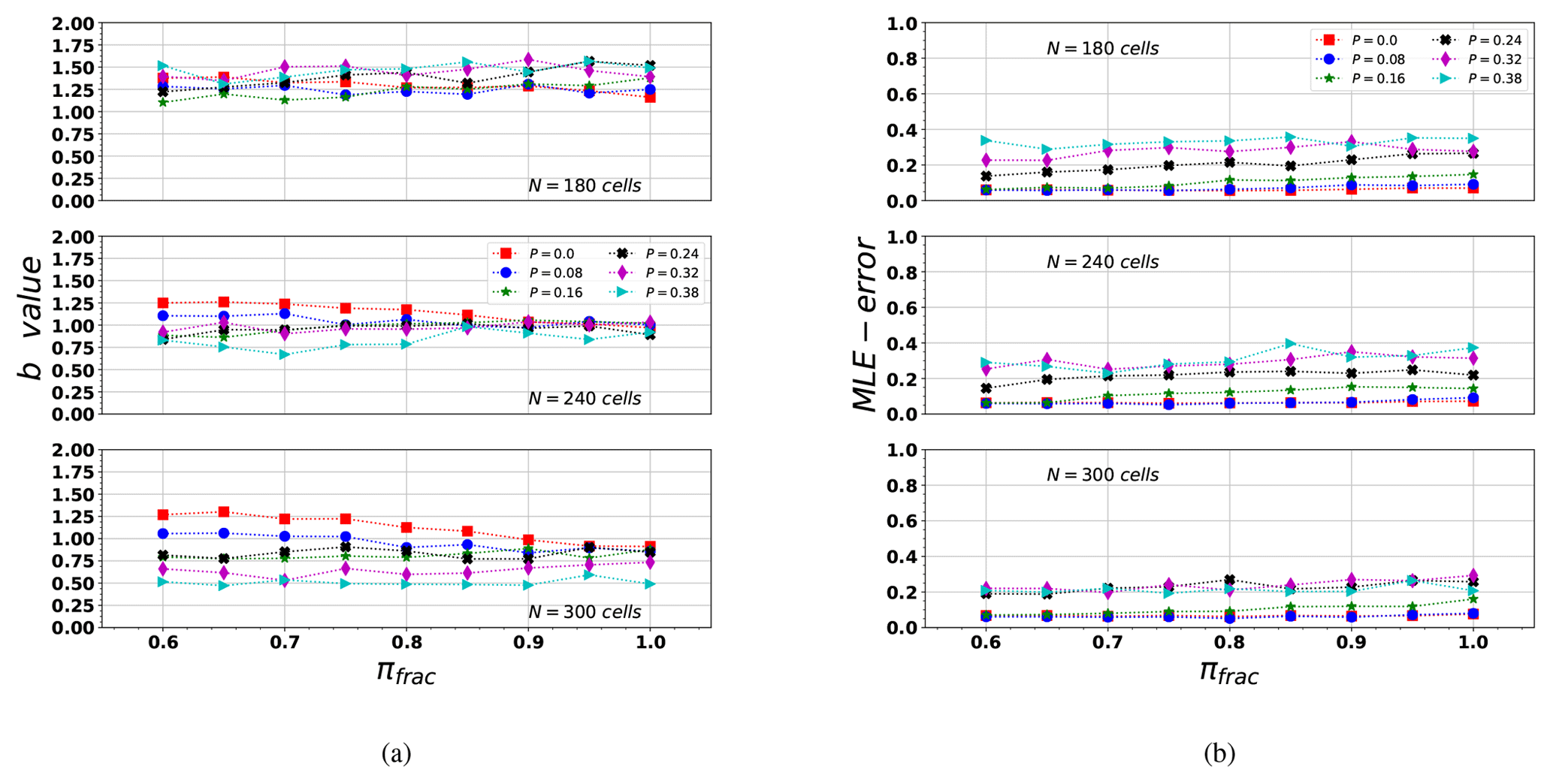

Figure 7(a) Mean magnitude (〈M〉) and (b) maximum magnitude (max(M)) computed for different synthetic series considering three input parameters (N, P, πfrac). From top to bottom, N=180, N=240, and N=300 (cells per lateral size in the domain).
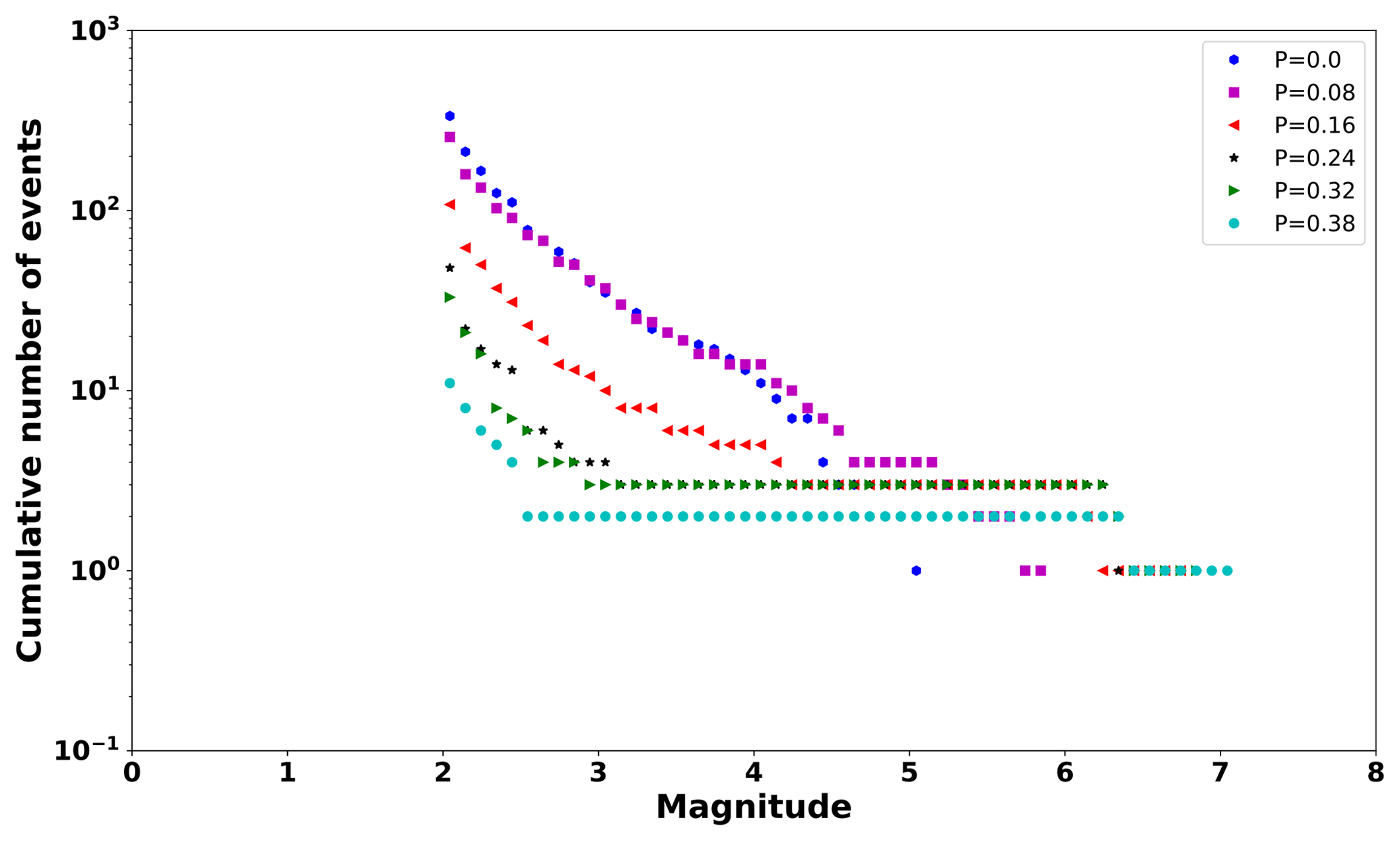
Figure 8Frequency–magnitude distribution computed in one synthetic series as example. Each marker indicates different P values, P=0 (dark blue circles), P=0.08 (magenta squares), P=0.16 (red triangles), P = 0.24 (black stars), P=0.32 (green triangles), and P=0.38 (turquoise circles). As P decreases, the distribution approaches a Gutenberg–Richter type relation (Eq. A7).
The results of the mean and maximum magnitudes are depicted in Fig. 7.
-
From Fig. 7a, we observe that the mean magnitude is independent of πfrac and to a lesser extent of P. It is worth pointing out that the b values are similar to those shown in Table 3 when Mmin≈2 or 2.5.
-
Fig. 7b shows that, in our model, an aftershock with a magnitude such as that of the largest Northridge aftershock magnitude (MW=5.9) is obtained for a non-unique combination of parameters. When P>0.08 and πfrac>0.7, this magnitude is overestimated. Given that the largest aftershock has a magnitude MW=5.9, larger-magnitude values are not described in the series.
From Figs. 6 and 7, we observe that the best range of b values, similar to that obtained for Northridge sequence, is for , and N≥240.
5.1.3 Hurst exponent of synthetic catalogs
Figure a and b show the results of the Hurst exponent for inter-event distance H(Δ) and inter-event time H(τ) (Eq. A6).
-
The re-scaled range analysis of the Δ(r) series reveals their independence on N and πfrac but shows a slightly higher dependence with P. In general, as P increases, H(Δ) also increases. As P decreases, H(Δ)→0.5, implying that the system tends to a random behavior of the inter-event epicentral distribution. However, H(Δ) always remains similar to the values of Table 3 for P≈0. Gkarlaouni et al. (2017) showed that the seismicity in the Corinth rift (Greece) corresponded to H(Δ)→0.5 as the threshold magnitude decreased.
-
The analysis of H(τ) reveals in general values >0.5, which implies a persistence in the dynamic system of inter-event times; i.e., the behavior of future inter-event time can be extrapolated from previous behavior. As P increases, the persistence of H(τ) also increases, which may be related to the MO trend (discussed below). The influence of πfrac over H(τ) is not clear; however, the number of events decreases when we take a larger cutoff magnitude, and this fact could affect the re-scaled range statistics.
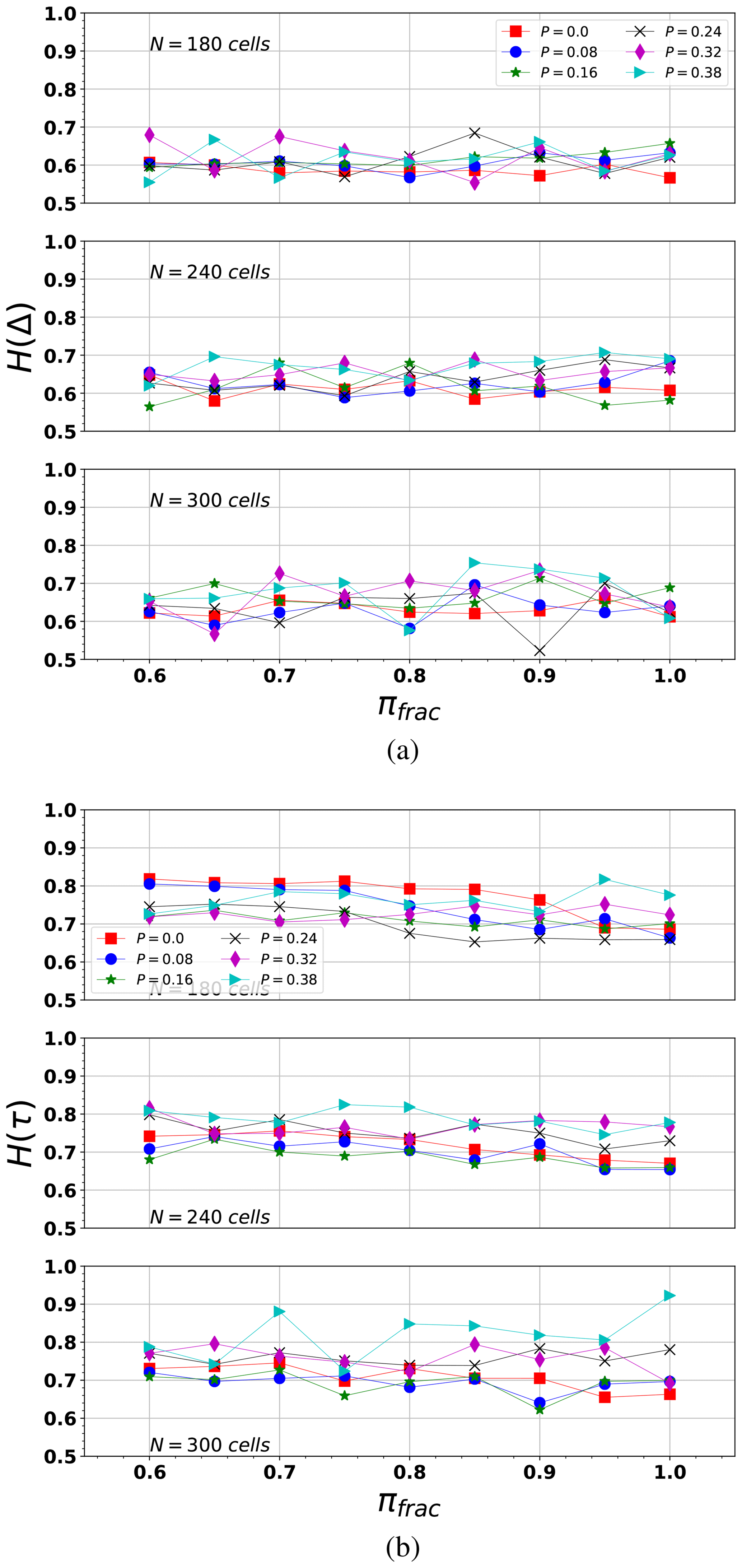
Figure 9Hurst exponent values (a) H(Δ) and (b) H(τ) computed for different synthetic series considering three input parameters (N, P, πfrac). From top to bottom, N=180, N=240, and N=300 (cells per lateral size in the domain).
5.1.4 MO parameters in synthetic catalogs
The MO empirical law requires careful analysis in our FBM implementation. First of all, we must take into account that we are using dimensionless time (see Eq. 3). Our cumulative time, Tj, is computed using Eq. (4). For example, considering the input values of P=0.08, πfrac=0.90, and Nx=180, if we include all simulated events (minor events and synthetic aftershocks) together (e.g., Fig. 10a), we get a satisfactory MO fit, with p=1.1, c=1.5, K = 11 991.3, and rms=675.0. But if we use only the time occurrence of the simulated aftershocks (S(NA)), the parameters depart from the expected trend (e.g., Fig. 10b), obtaining p=1.9, c=4.9, K=1571.9, and rms=10.8. From Fig. 10b, two regions are distinguished by the density of events, since for the first interval of time the density is larger (blue) than for the subsequent region (green). As a consequence, the MO fit is deviated adjusting for events in the blue region. Real aftershocks do not always follow a single MO decay trend (Utsu and Ogata, 1995). Moreno et al. (2001) developed an alternative model to understand this phenomenon called leading and cascade (LA-CAS) events. This model proposes a separation of earthquakes in two groups: one that strictly follows the MO hypothesis (called leading aftershocks; LAs) and those called cascades, which are the events that occur between two consecutive LAs. Note that to obey the MO relation, the inter-event times must increase monotonically. In our previous work (Monterrubio et al., 2015), we tested the LA-CAS algorithm to study the temporal behavior of three real aftershock sequences. We applied the LA-CAS algorithm to the synthetic earthquakes series, as illustrated in Fig. 10b. After segregating the events in LA and CAS, we obtain a better fit to the MO relation for the LA series (Fig. 11, LA: p=0.9, c=0.1, K=5.1, and rms=1.2). The full parametric results computed from the MO relations are shown in Fig. 12a and b.
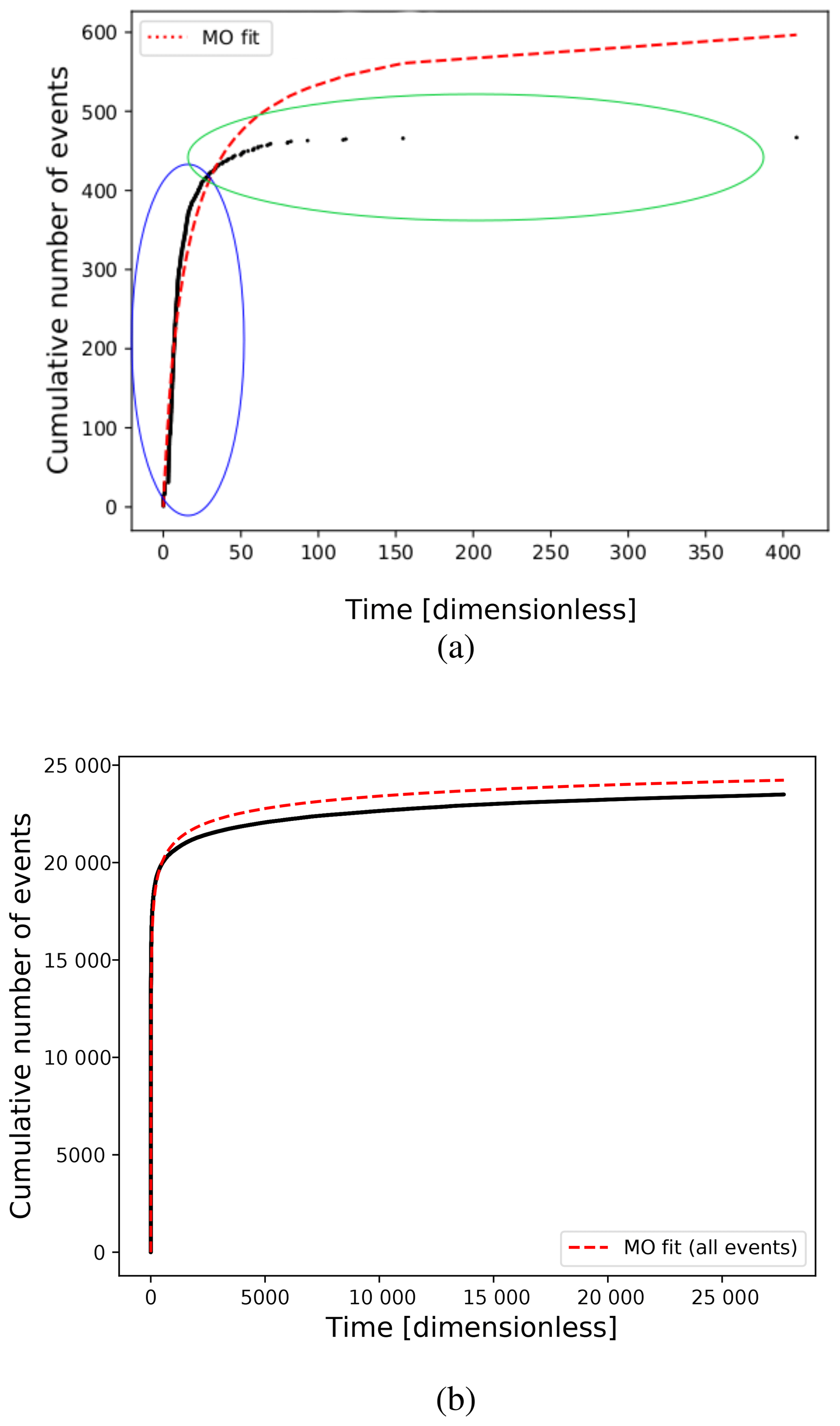
Figure 10Modified Omori relation (Eq. A11) (dashed red line) fitting for one simulation with P=0.08, πfrac=0.90, N=180. (a) Synthetic aftershocks series for Mmin=2.0 (black dots). Two regions are distinguished, where the density of events in the blue region is much larger than that in the green. (b) All events generated (minor normal and avalanches) (in black dots). A high and homogeneous data density along the plot is observed.

Figure 11MO fitting for the leading aftershock (LA) series computed for the same synthetic series of Fig. 10.
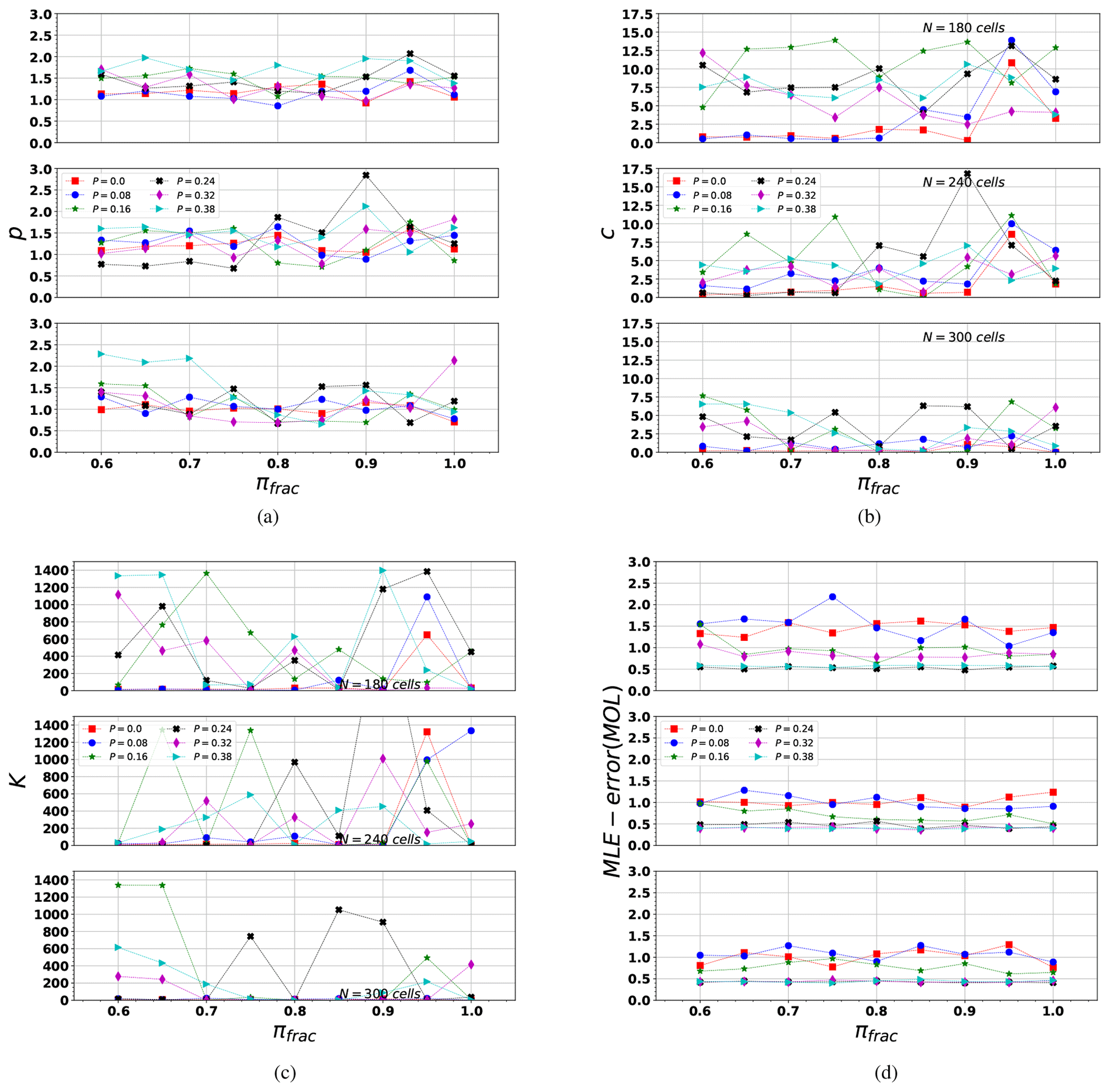
Figure 12Modified Omori parameters computed in the LA synthetic series: (a) p, (b) c, (c) K, and (d) rms. Each marker is obtained by different synthetic series considering three input parameters (N, P, πfrac). From top to bottom, N=180, N=240, and N=300 (cells per lateral size in the domain).
The MO parametric results provide information of the temporal behavior in the simulated series. We observe that P<0.08 implies p and c values close to the expected Northridge values (see Table 3). However, after segregating LA and CAS, the number of events decreases, so the value of K is much lower than expected. These results indicate that series with an initial load configuration organized with a probability P>0.08 depart from a typical MO behavior. This occurs because the aftershock series produced with larger initial organization probabilities (P>0.08) tend to generate temporal series with very short elapsed times (Eq. 3), and larger avalanche clusters, which does not follow a typical MO distribution. The closest behavior to the observed MO parameters of Northridge (Table 3) occurs for P≤ 0.08 and πfrac>0.7.
5.2 Trigger and shadow regions
The load-transfer value π(x,y) is highly relevant to reproduce temporal, magnitude, and spatial patterns of real series (Monterrubio et al., 2015). Considering this fact, we are also interested in studying the implication of this value in the aftershock productivity, in particular for off-fault regions. To test the productivity as a function of πbkg, two extreme values are considered for πbkg=0.25 and πfrac=0.65. In Fig. 13, we observed that activity in background (non-faulting) cells largely decreases for small πbkg values. This occurs because for low π values, the probability to produce an event with larger ruptured area decreases (Fig. 14). The results suggests that variations in πbkg for different regions of the domain can lead to producing shadow and triggered regions, giving a scenario closer to a real case (King et al., 1994; Stein, 1999; Hainzl et al., 2014). The lack of the depth (3-D) in our model could produce bias in the shadow region interpretation and is a limitation to a closer description of the phenomenon. However, in this study, our first attempt is more focused on the parametric implications of the fault regions included in the model as “weak” areas. We expect that the integration of triggered and shadow regions will be plausible in future implementations to improve the results.

Figure 13Epicentral spatial distribution for two examples: (a) P=0, πfrac=0.95, N=180, and πbkg=0.25; and (b) P=0, πfrac=0.95, N=180, and πbkg=0.65. The different circles sizes represent the equivalent magnitude according to the legend. The center of each circle is the epicentral or nucleation point of each synthetic event. The major events occur over the faults.

5.3 Results summary: synthetic catalogs
Lastly, we estimated the error between the real and synthetic statistical values using a measure similar to the Euclidean distance . However, in our case, is referred to a normalized parametric space because of the different units in the parameters, and it is defined as
where ps = [D0, 〈MW〉, b value, Mmax, Mmin, H(Δ), H(τ), p, c] is the vector that contains the values of the series generated with a given set of input parameters P,πfrac, and N. Similarly, the vector contains the values for the Northridge series considering four different minimum magnitudes (Table 3). We computed for the 162 combinations of P,πfrac, and N, each one with three realizations. In Table 4, we show the minimum of for . The minimum Euclidean distance occurs when we consider the NOR series with Mmin=2.0. It is worth mentioning that the minimum magnitude of the synthetic aftershocks considered in this work is also ≈2.0. The results show that the most appropriate set of parameters to model this data series is P=0, πfrac=0.90 using N=300 cells. Figure 15 shows the Euclidean distance between the sequence generated by NOR using the set of parameters obtained with Mmin=2.0 and its real values. In Fig. 16, we show an example of a spatial distribution of events and its related GR relation, using the set P=0, πfrac=0.95, and N=300. As shown in Fig. 16, the largest aftershocks have its epicenter on the fault's cells (M>3.5). The epicenters are depicted with a blue star. This scatter plot also shows that the smallest events usually occur spread out. The relation of the magnitude and the cumulative number of events, generated in this example, shows a GR fit with a similar b value to that computed in Table 3.
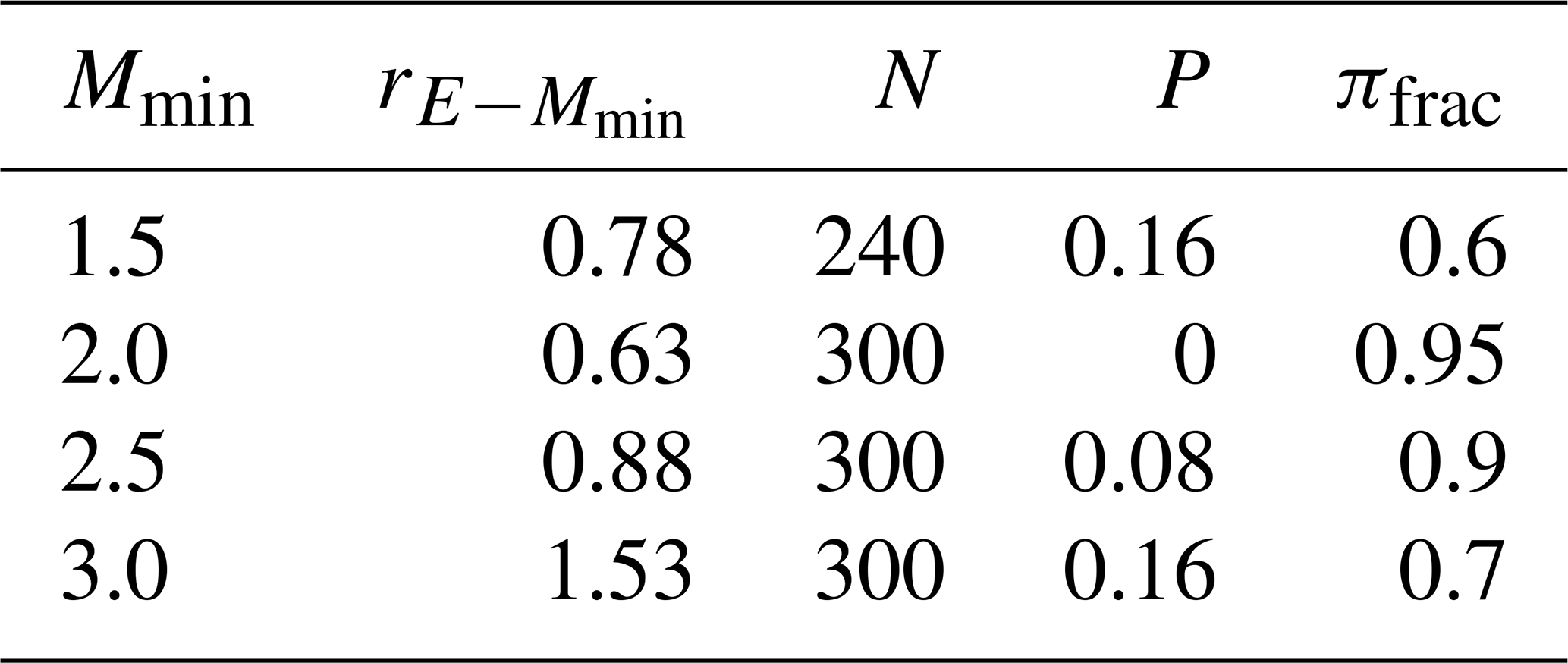
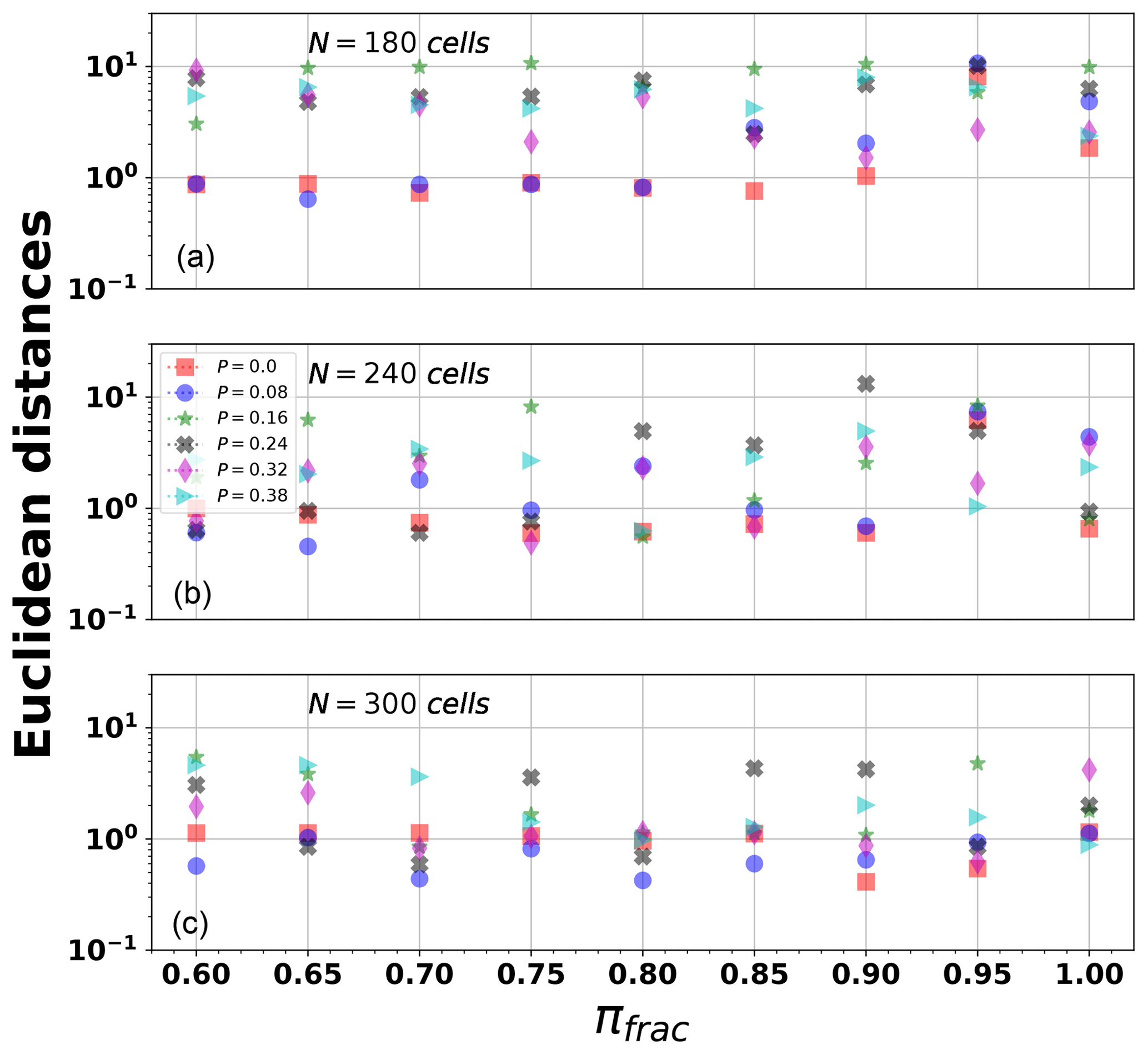
Figure 15Euclidean parametric distance (Eq. 7) computed for the synthetic series (Mmin=2.0) considering three input parameters (N, P, πfrac). From panel (a) to (c), N=180, N=240, and N=300 (cells per lateral size in the domain).

Figure 16(a) Example of the spatial distribution of simulated events for a particular FBM realization with P=0, πfrac=0.95, and N=300. Circular areas depict the equivalent magnitude–area relation computed from Eq. (6). Star markers indicate the epicenter of each simulated earthquake. (b) Gutenberg–Richter fit of simulated events (P=0, πfrac=0.95, πbkg=0.65, and N=300).
The main goal of this study is to integrate prior knowledge of the spatial geometry of faults in the implementation of the FBM algorithm, improving the model previously proposed in Monterrubio-Velasco et al. (2017). As it was pointed out, to introduce the fault system geometry we assume some cells to be weaker than the rest representing faults in the bi-dimensional array. This “weakness” is assigned by a single parameter called πfrac. The lack of the depth dimension may leave out information about the full phenomenon. However, it is a first attempt to test the FBM as an aftershock simulator including complex features. The main advantage of the present model is the reduced number of equations to be solved in comparison with deterministic models for similar purposes and the low number of parameters used to describe the model dynamics (, and NT). To validate our model, we used as an example the geometry of the Northridge fault system and the statistics of the aftershocks. Note that this model version describes the relaxation process after a mainshock. Therefore, we do not discuss or simulate the mainshock or foreshocks. In particular, we explored the power laws' exponents ( parameters) in relation to the model parameters (Sect. A1). Other models have been proposed to describe, with a simplified mechanism, the statistics of earthquakes, such as the two-fractal overlap model (Bhattacharya et al., 2009) or the Olami–Feder–Christensen (OFC) model (Olami et al., 1992). In particular, the OFC model has a very similar algorithmic to our proposed model (Kawamura et al., 2012), but our model yields similar results with fewer input parameters and it is simpler to implement. As a statistical modeling tool, we need a parametric analysis to properly fit observational data. In our study, we have searched the range of values that generate synthetic series capable of reproducing the statistical relations of real aftershock series. In particular, we explored three (πfrac,P and N) of the five free parameters to quantify their leading role in the model. We point out that πbkg and ρ are assumed as constants following results in Monterrubio et al. (2015) and Monterrubio-Velasco et al. (2017). In agreement with Monterrubio et al. (2015), we also confirm that the transferred load value π is the most critical parameter in order to reproduce temporal, magnitude, and spatial patterns of real series. Our results also suggest that variations in π for different regions of the domain might generate shadow regions (King et al., 1994; Stein, 1999; Hainzl et al., 2014). The initial load configuration, controlled by P, results as a determinant to describe the final statistical features in the model. In particular, the results indicate that P and πfrac are inversely proportional. As we increase πfrac, a small value of P is required to reproduce aftershock statistics. If the fault geometry is not considered in the model (πbkg=πfrac), the particular range of found in Monterrubio-Velasco et al. (2017) is required to capture statistical patterns.
The results are sensitive to the size of the domain. An exhaustive parametric analysis using machine learning techniques to classify the synthetic series as function of the input parameters (the size N, P, and πfrac) was carried out in Monterrubio-Velasco et al. (2018). In Fig. 17 from Monterrubio-Velasco et al. (2018), we show the mean error of three different ML classification algorithms (random forests, supported vector machine, and flexible discriminant analysis) as a function of the domain (grid) size. The figure shows that as the grid size is increased, the classification error decreases, meaning that large grid sizes allow us to distinguish among the different properties. In other words, for small grid size, the difference is indistinguishable, while larger grid sizes are able to capture the differences. We observe the results using as classification two input parameters: P (in red) and πfrac (in blue). When we use the P parameter, we observe that the size domain has to increase in order to reduce the mean classification error, and it becomes the minimum for N≥300. On the other hand, if we want to classify the synthetic catalogs considering πfrac, the figure shows that the error classification reaches a minimum value for lower grid sizes N≥200. So, if we consider the case of P=0, and the classification is based on πfrac, then a proper grid size used to model aftershocks, including faults, is N≥200. We can confirm that an optimization of the parametric search using classification machine learning techniques can be very useful in this stochastic model.
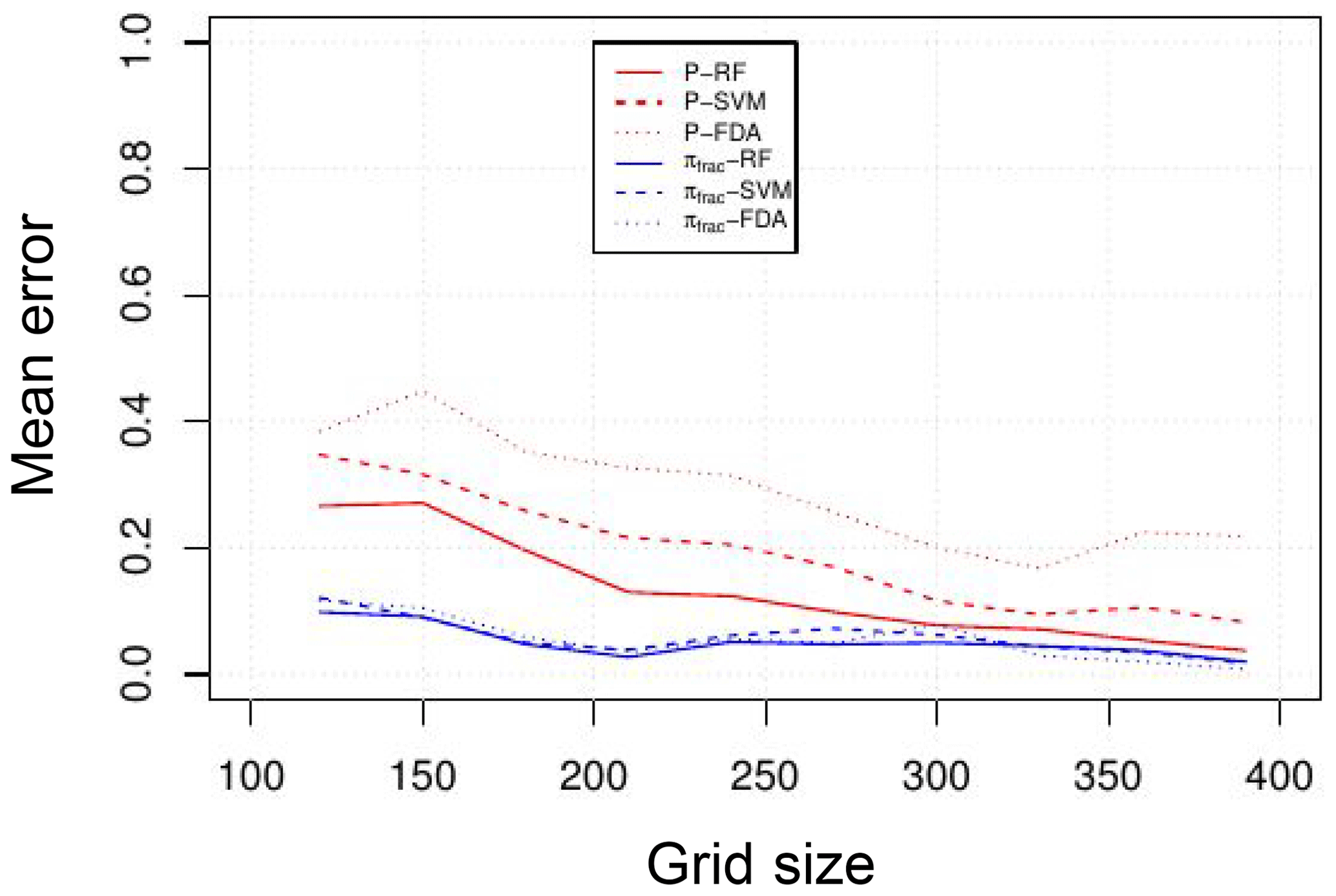
Figure 17Mean error of three different ML classification algorithms (random forests, supported vector machine, and flexible discriminant analysis) as a function of the domain size (figure from Monterrubio-Velasco et al., 2018).
Considering the example of Northridge, our results suggest that the best combination of parameters to approximate to real cases depends on the minimum magnitude of the real catalogs, as shown in Table 4. Related to the completeness magnitude, Davidsen and Baiesi (2016) define the short-term aftershock incompleteness (STAI) as a phenomenon that arises from overlapping waveforms and/or detector saturation, such as events that are missed in the coda of preceding ones. One important consequence of STAI is an increase in the local magnitude of completeness, since small events are not well recorded. It is worth noting that in this work we are not analyzing the STAI phenomena because we are not explicitly modeling this process. We use the Northridge catalog obtained by the Southern California Seismic Network (SCSN), and we analyze it as a “final” catalog. In our statistics and analysis applied to the real catalog, we consider different magnitude cutoffs, as shown in Table 3. The cutoff magnitude is not related to the time. On the other hand, it is noteworthy that our model is not affected by the STAI, because this phenomenon arises from overlapping waveforms, and in our approach we are not considering this physical process. To modify the minimum magnitude in the synthetic catalogs, we only filter the events with small rupture areas.
The usefulness of this stochastic model is its capability to generate a large number of scenarios with statistical properties similar to real cases, with low computational cost and a low number of free parameters.
We present a novel model simulation of aftershock sequences that incorporates a 2-D spatial distribution of faults. The representation of faults is carried out by assigning weak cells embedded in a background of “normal” cells. However, this model fulfills statistical properties of aftershock when it is well tuned. We choose statistical relations which describe the aftershocks' behavior in space, magnitude, and time. By means of a parametric study, we have found the range of values that generates synthetic series capable of reproducing the statistical relations of real aftershock events. In particular, we have used the Northridge fault system geometry projected on the surface and its aftershock sequence as a study case. We conclude that the initial load configuration (quantified by parameter P), which specifies the randomness in the background load distribution and the ratio of transferred load for a faulting cell πfrac are the key parameters that control the earthquake's statistical patterns in FBM-simulated events. Moreover, these parameters are complementary; i.e., in absence of fault geometry information (πfrac=πback), values in the range ensure statistical compatibility with real aftershocks. In particular, for πfrac=π and N=180, we recover the results obtained previously without fault information (Monterrubio-Velasco et al., 2017). On the other hand, when fault geometry is available, as in the case of the Northridge fault system, the results obtained in this work show that, in order to reproduce statistical characteristics of the real sequence, larger πfrac values () and very low values of P () are needed. This implies the important corollary that a very small departure from an initial random load configuration is required to initiate a rupture sequence which conforms to observed statistical properties such as the Gutenberg–Richter law, Omori law, and fractal dimension. In summary, the proposed model is a useful tool to model aftershock scenarios by means of its inherent statistical patterns in time, space, and magnitude. Moreover, the model circumvents the high complexity related to the derivation of deterministic models of earthquake rupture phenomena. We demonstrated the ability of the model to simulate statistically consistent data with those of real scenarios using only a few input parameters. Our model can be an alternative to the study of the complex behavior of earthquakes. Future work will focus on optimization of the parametric search using machine learning techniques and extensions towards a 3-D FBM version that incorporates the depth dimension into the model.
The data and the numerical code can be obtained upon request to the author, Marisol Monterrubio-Velasco (marisol.monterrubio@bsc.es, marisolmonterrub@gmail.com).
A1 Statistical and fractal relations
A1.1 Fractal dimension
Fractured systems, including lithospheric faults, are scale invariant in a large scale range being characterized by the power law (Turcotte, 1997; Mandelbrot, 1989). The fractal dimension is an important parameter used to characterize fracture patterns in heterogeneous materials (Hirata and Imoto, 1991). In seismicity, it provides a quantitative measure of the spatial clustering of epicenters and hypocenters (Roy and Ram, 2006). There are many fractal dimension definitions and descriptions used to characterize a dynamical system, for example, the capacity dimension, D0 (Nanjo et al., 1998; Legrand et al., 2004), the information dimension, D1, or the correlation dimension, D2 (Grassberger and Procaccia, 1983). For the purpose of our study, we will use only the capacity dimension, D0, since it is one of the most studied fractal dimensions for the spatial distribution in earthquakes (epicenter and hypocenter); also, we are interested in evaluating the capacity of the spatial distribution to occupy the space in which it is embedded. Future research could consider a multifractal analysis for synthetic and real series.
The generalized fractal dimension, Dq, is used to compute different fractal dimensions (Eneva, 1994; Márquez-Rámirez et al., 2012).
where
with q is a positive or negative real number, N the number of samples, the inter-event distance for consecutive events, ℋ the Heaviside step function, and r a threshold distance value to evaluate ℋ. With this method, we compute the probability of a pair of points in the system being closer than the threshold r. Equation (A2) has the property that , , and . Barriere and Turcotte (1994) assume that if the spatial distribution of earthquakes is fractal, then the faults must have a fractal distribution as well. Turcotte (1997) showed that the capacity dimension of epicentral and hypocentral distributions yields a fractal distribution with an exponent D0≈1.6 and D0≈2.5, respectively.
A1.2 Re-scaled range analysis and Hurst exponent
The re-scaled range (R∕S) analysis, and more specifically the Hurst exponent H (Hurst et al., 1965), offers a criterion for evaluating the predictability of a complex dynamic system (Feder, 1988; Goltz, 1997). The R∕S analysis can be interpreted as a method to measure the long-range correlation in time series. Some applications of this fractal technique in different fields of geophysics and geology are given in Korvin (1992) and Turcotte (1997). R∕S analysis on earthquake sequences was first implemented by Lomnitz (1994) and applied to an analysis of the seismicity of the south Iberian Peninsula (Lana et al., 2005), the Corinth rift and Mygdonia graben in Greece (Gkarlaouni et al., 2017), or aftershocks in southern California (Monterrubio-Velasco, 2013).
With a set of observations in a time series, the mean, m, of the series is computed and a mean adjusted series is created, following
for . Then, a cumulative deviate series Z can be computed as
Then, R∕S is the ratio between the range Rt and standard deviation St, where the range is computed as
and St is the standard deviation of . Hurst used the following power-law relationship to determine the predictability of time series (Hurst et al., 1965):
where H=0.5 indicates randomness in the series; i.e., the samples are not correlated with one another. H>0.5 indicates some degree of predictability or temporal persistence in the system. Lastly, indicates anti-persistence; i.e., an increasing (decreasing) trend in the past implies a decreasing (increasing) trend in the future (Correig et al., 1997).
A1.3 Gutenberg–Richter law
The GR (sometimes referred to as the Gutenberg–Richter Ishimoto–Ida) law is considered one of the major manifestations of self-organized criticality in a natural system. It has been observed that earthquake magnitude distributions fit a GR power law (Gutenberg and Richter, 1942):
where N(≥M) is the cumulative number of events with magnitude greater than or equal to M. The slope b describes the ratio between small- and large-magnitude events and is usually in the range (Evernden, 1970; Ozturk, 2012; Svalova, 2018), whereas a is proportional to the earthquake productivity (i.e., the seismicity rate).
In particular, b is one of the most useful statistical parameters for describing the size scaling properties of seismicity. For example, Ozturk (2012) concludes that this parameter can be used to differentiate tectonic regions. Similarly, Zuniga and Wyss (2001) used the b value to identify most and least likely locations of earthquakes in the Mexican subduction zone.
In the rest of the present work, we apply the maximum likelihood method (MLE) to estimate b (Aki, 1965):
where Mmin is the minimum magnitude of events considered in the study, and ΔM is related to the precision of the recorded magnitude; in our case, we consider ΔM=0.1. The standard error of b, σ(b), is computed as (Shi and Bolt, 1982):
where σ(〈M〉) is the standard deviation of the magnitude series
where n is the number of elements in the series.
A1.4 Modified Omori law
The temporal behavior of aftershocks is commonly described by the MO law (Omori, 1894; Utsu and Ogata, 1995) defined as
where n(t) is the generation rate of aftershocks at time t after the mainshock, whereas K, c, and p are parameters to be determined. The p parameter controls the aftershock activity decay and is related to the physical conditions in the fault zone (Kisslinger, 1996; Ogata, 1999). Its value is typically p≈1. The constant c eliminates the uniqueness of occurrence rate at t=0 (Kisslinger, 1996), the productivity K is a constant that depends on the total number of aftershocks. Then the cumulative number of aftershocks, N(t), of the earthquake count at time t since the mainshock at t=0, can be obtained by integrating Eq. (A11), resulting in
A2 Algorithm
The main algorithm (Algorithm 1; Sect. A2.1), for each discrete step k, updates the rupture probability F of each cell, finding the cell boasting the largest load and then finding whether that load exceeds the given load threshold σth. If so, rupture is initiated and an avalanche occurs due to recurrent load transfer and rupture of neighboring cells. Whenever no cell has sufficient load to reach σth, a regular, i.e., minor, event is triggered, which ensures load transfer and hence makes it more likely that an avalanche, i.e., major, event will occur in the next time steps. The initialization step is shown in Algorithm 2 (Sect. A2.2) and the rupture process is depicted in Algorithm 3 (Sect. A2.3). Notice that rupture relies on a transfer-ratio weight σN for the horizontal and vertical transfer and σD for diagonal transfer, which are further global parameters to prescribe.
A2.1 Main algorithm
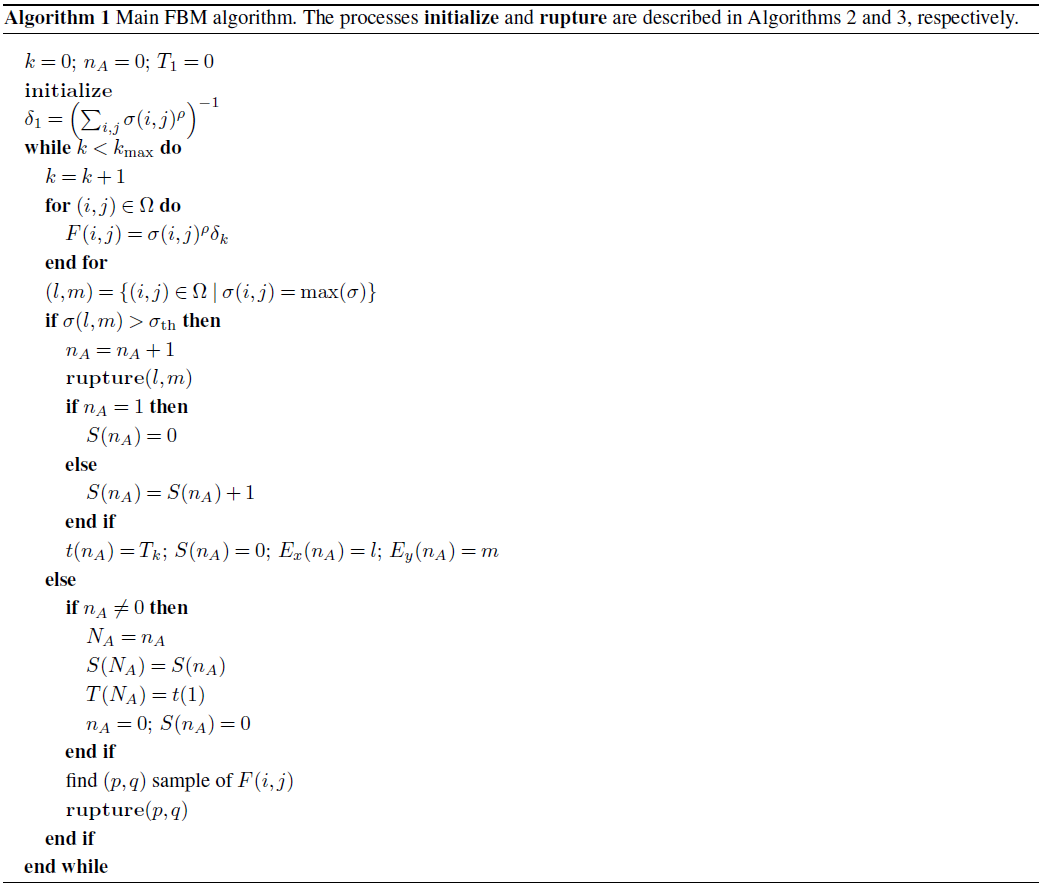
A2.2 Algorithm 2

A2.3 Algorithm 3

MMV developed the numerical code. MMV, FRZ, JCCJ, VMR, and JdlP provided guidance and theoretical advice during the study. All the authors contributed to the analysis and interpretation of the results. All the authors contributed to the writing and editing of the paper.
The authors declare that they have no conflict of interest.
We would like to thank the editor and the reviewers for their insights and suggested improvements of this work. Marisol Monterrubio-Velasco thanks CONACYT for initially supporting this research project. This project has received funding from the European Union's Horizon 2020 research and innovation program under Marie Skłodowska-Curie grant agreement no. 777778 MATHROCKS and from the Spanish Ministry Project TIN2016-80957-P. Initial funding for the project through grant UNAM-PAPIIT IN108115 is also gratefully acknowledged. This project has received funding from the European Union's Horizon 2020 Programme under the ChEESE Project (https://cheese-coe.eu, last access: 30 August 2019), grant agreement no. 823844.
The research leading to these results has received funding from the European Union's Horizon 2020 Programme under the ChEESE Project (https://cheese-coe.eu/), grant agreement no. 823844. This research has been supported by the CONACYT (grant no. 220969), the European Commission (Horizon 2020 (grant nos. 823844 and 777778)), the Spanish Ministry Project (grant no. TIN2016-80957-P), and UNAM-PAPIIT (grant no. IN108115).
This paper was edited by CharLotte Krawczyk and reviewed by Philippe Jousset, CharLotte Krawczyk, and one anonymous referee.
Adamatzky, A. and Martínez, G. J.: Designing beauty: The art of cellular automata, Vol. 20, Springer International Publishing AG, Switzerland, 2016. a
Aki, K.: Maximum likelihood estimated of b in the formula log and its confidence limits, Bull. Earthq. Res. Inst. Tokyo Univ., 43, 237–239, 1965. a, b
Andersen, J. V., Sornette, D., and Leung, K.-T.: Tricritical behavior in rupture induced by disorder, Phys. Rev. Lett., 78, 2140, https://doi.org/10.1103/PhysRevLett.78.2140, 1997. a
Bak, P. and Creutz, M.: Fractals and self-organized criticality, in: Fractals in science, 27–48, Springer-Verlag Berlin Heidelberg, Germany, 1994. a
Barriere, B. and Turcotte, D.: Seismicity and self-organized criticality, Phys. Rev. E, 49, 1151, https://doi.org/10.1103/physreve.49.1151, 1994. a, b, c
Bezanson, J., Edelman, A., Karpinski, S., and Shah, V. B.: Julia: A fresh approach to numerical computing, SIAM Rev., 59, 65–98, https://doi.org/10.1137/141000671, 2017. a
Bhattacharya, P., Chakrabarti, B. K., and Samanta, D.: Fractal models of earthquake dynamics, Reviews of Nonlinear Dynamics and Complexity, edited by: Schuster, H. G., 107–158, Wiley – VCH Verlag GmbH & Co. KGaA, Weinheim, Germany, 2009. a
Castellaro, S. and Mulargia, F.: A simple but effective cellular automaton for earthquakes, Geophys. J. Int., 144, 609–624, 2001. a
Coleman, B. D.: Time dependence of mechanical breakdown phenomena, J. Appl. Phys., 27, 862–866, 1956. a, b, c
Correig, A. M., Urquizu, M., Vila, J., and Marti, J.: Analysis of the temporal ocurrence of seismicity at deception Island (Antarctica). A nonlinear approach, Pure and Applied Approach, 149, 553–574, 1997. a, b
Daniels, H.: The statistical theory of the strength of bundles of threads. I, P. Roy. Soc. Lond. A Mat., 183, 405–435, 1945. a
Davidsen, J. and Baiesi, M.: Self-similar aftershock rates, Phys. Rev. E, 94, 022314, https://doi.org/10.1103/PhysRevE.94.022314, 2016. a
Eneva, M.: Monofractal or multifractal: a case study of spatial distribution of mining-induced seismic activity, Nonlin. Processes Geophys., 1, 182–190, https://doi.org/10.5194/npg-1-182-1994, 1994. a
Evernden, J.: Study of regional seismicity and associated problems, B. Seismol. Soc. Am., 60, 393–446, 1970. a
Feder, J.: Fractals (physics of solids and liquids), Plennum, New York, 1988. a
Georgoudas, I. G., Sirakoulis, G. C., and Andreadis, I.: Modelling earthquake activity features using cellular automata, Math. Comput. Model., 46, 124–137, 2007. a
Gkarlaouni, C., Lasocki, S., Papadimitriou, E., and George, T.: Hurst analysis of seismicity in Corinth rift and Mygdonia graben (Greece), Chaos Soliton. Fract., 96, 30–42, 2017. a, b
Godano, C., Alonzo, M., and Bottari, A.: Multifractal analysis of the spatial distribution of earthquakes in southern Italy, Geophys. J. Int., 125, 901–911, 1996. a
Goltz, C.: Fractal and chaotic properties of earthquakes, in: Fractal and Chaotic Properties of Earthquakes, 3–164, Springer, Berlin, Heidelberg, Germany, 1997. a
Gómez, J., Moreno, Y., and Pacheco, A.: Probabilistic approach to time-dependent load-transfer models of fracture, Phys. Rev. E, 58, 1528, https://doi.org/10.1103/PhysRevE.58.1528, 1998. a
Grassberger, P. and Procaccia, I.: Measuring the strangeness of strange attractors, Physica D, 9, 189–208, 1983. a
Gutenberg, B. and Richter, C. F.: Earthquake magnitude, intensity, energy, and acceleration, B. Seismol. Soc. Am., 32, 163–191, 1942. a, b
Hainzl, S., Moradpour, J., and Davidsen, J.: Static stress triggering explains the empirical aftershock distance decay, Geophys. Res. Lett., 41, 8818–8824, 2014. a, b
Hanks, T. and Bakun, W. H.: M-log A observations of recent large earthquakes, B. Seismol. Soc. Am., 98, 490–494, 2008. a
Hansen, A., Hemmer, P. C., and Pradhan, S.: The fiber bundle model: modeling failure in materials, John Wiley & Sons, Hoboken, New Jersey, USA, 2015. a
Hauksson, E., Jones, L. M., and Hutton, K.: The 1994 Northridge earthquake sequence in California: Seismological and tectonic aspects, J. Geophys. Res.-Sol. Ea., 100, 12335–12355, 1995. a
Hirata, T. and Imoto, M.: Multifractal analysis of spatial distribution of microearthquakes in the Kanto region, Geophys. J. Int., 107, 155–162, 1991. a, b, c
Hurst, H. E., Black, P. P., and Simaika, Y. M.: Long-term storage: an experimental study Constable, London, 1965. a, b
Kagan, Y. and Knopoff, L.: Spatial distribution of earthquakes: the two-point correlation function, Geophys. J. Int., 62, 303–320, 1980. a
Kawamura, H., Hatano, T., Kato, N., Biswas, S., and Chakrabarti, B. K.: Statistical physics of fracture, friction, and earthquakes, Rev. Mod. Phys., 84, 839–884, https://doi.org/10.1103/RevModPhys.84.839, 2012. a
King, G. C., Stein, R. S., and Lin, J.: Static stress changes and the triggering of earthquakes, B. Seismol. Soc. Am., 84, 935–953, 1994. a, b
Kisslinger, C.: Aftershocks and fault zone properties, Geophys. J. Int., 38, 1–36, 1996. a, b
Kloster, M., Hansen, A., and Hemmer, P. C.: Burst avalanches in solvable models of fibrous materials, Phys. Rev. E, 56, 2615–2625, https://doi.org/10.1103/PhysRevE.56.2615, 1997. a
Korvin, G.: Fractal models in the earth sciences, Elsevier Science Ltd, Amsterdam, the Netherlands, 1992. a
Kroll, K. A.: Complex Faulting in the Yuha Desert: Implications for Fault Interaction, University of California, Riverside, 2012. a
Kun, F., Hidalgo, R. C., Raischel, F., and Herrmann, H. J.: Extension of fibre bundle models for creep rupture and interface failure, Int. J. Fracture, 140, 255–265, 2006a. a, b
Kun, F., Raischel, F., Hidalgo, R., and Herrmann, H.: Extensions of fibre bundle models, Modelling critical and catastrophic phenomena in geoscience, Springer, Berlin, Heidelberg, Germany, 57–92, 2006b. a
Lana, X., Martínez, M. D., Posadas, A. M., and Canas, J. A.: Fractal behaviour of the seismicity in the Southern Iberian Peninsula, Nonlin. Processes Geophys., 12, 353–361, https://doi.org/10.5194/npg-12-353-2005, 2005. a
Legrand, D., Villagómez, D., Yepes, H., and Calahorrano, A.: Multifractal dimension and b value analysis of the 1998–1999 Quito swarm related to Guagua Pichincha volcano activity, Ecuador, J. Geophys. Res.-Sol. Ea., 109, B01307, https://doi.org/10.1029/2003JB002572, 2004. a
Lomnitz, C.: Fundamentals of earthquake prediction, Wiley, New York, USA, 1994. a
Mandelbrot, B. B.: Multifractal measures, especially for the geophysicist, Pure Appl. Geophys., 131, 5–42, 1989. a
Mandelbrot, B. B. and Pignoni, R.: The fractal geometry of nature, Vol. 173, WH Freeman, New York, 1983. a
Márquez-Rámirez, V. H., Nava Pichardo, F. A., and Reyes-Dávila, G.: Multifractality in Seismicity Spatial Distributions: Significance and Possible Precursory Applications as Found for Two Cases in Different Tectonic Environments, Pure Appl. Geophys., 169, 2091–2105, https://doi.org/10.1007/s00024-012-0473-9, 2012. a
Monterrubio, M., Lana, X., and Martínez, M. D.: Aftershock sequences of three seismic crises at southern California, USA, simulated by a cellular automata model based on self-organized criticality, Geosci. J., 19, 81–95, 2015. a, b, c, d, e, f
Monterrubio-Velasco, M.: Análisis estadístico y comportamiento fractal de las réplicas sísmicas del Sur de California, PhD thesis, Universitat Politècnica de Catalunya, Spain, 2013. a, b, c, d
Monterrubio-Velasco, M., Zúñiga, F., Márquez-Ramírez, V., and Figueroa-Soto, A.: Simulation of spatial and temporal properties of aftershocks by means of the fiber bundle model, J. Seismol., 21, 1623–1639, https://doi.org/10.1007/s10950-017-9687-8, 2017. a, b, c, d, e, f, g, h, i, j, k, l, m, n, o
Monterrubio-Velasco, M., Carrasco-Jiménez, J., Castillo-Reyes, O., Cucchieti, F., and de la Puente J.: A Machine Learning Approach for Parameter Screening in Earthquake Simulation, High Performance Machine Learning Workshop, 24–27 September 2018, Lyon, France, https://doi.org/10.1109/CAHPC.2018.8645865, 2018. a, b, c, d, e, f
Monterrubio-Velasco, M., Rodríguez-Pérez, Q., Zúñiga, R., Scholz, D., Aguilar-Meléndez, A., and de la Puente, J.: A stochastic rupture earthquake code based on the fiber bundle model (TREMOL v0.1): application to Mexican subduction earthquakes, Geosci. Model Dev., 12, 1809–1831, https://doi.org/10.5194/gmd-12-1809-2019, 2019. a, b
Moral, L., Gomez, J., Moreno, Y., and Pacheco, A.: Exact numerical solution for a time-dependent fibre-bundle model with continuous damage, J. Physica A, 34, 9983, https://doi.org/10.1088/0305-4470/34/47/305, 2001a. a, b
Moral, L., Moreno, Y., Gómez, J., and Pacheco, A.: Time dependence of breakdown in a global fiber-bundle model with continuous damage, Phys. Rev. E, 63, 066106, https://doi.org/10.1103/PhysRevE.63.066106, 2001b. a
Moreno, Y., Gómez, J., and Pacheco, A.: Self-organized criticality in a fibre-bundle-type model, Physica A, 274, 400–409, 1999. a
Moreno, Y., Correig, A., Gómez, J., and Pacheco, A.: A model for complex aftershock sequences, J. Geophys. Res.-Sol. Ea., 106, 6609–6619, 2001. a, b, c, d, e
Nanjo, K. and Turcotte, D.: Damage and rheology in a fibre-bundle model, Geophys. J. Int., 162, 859–866, 2005. a
Nanjo, K., Nagahama, H., and Satomura, M.: Rates of aftershock decay and the fractal structure of active fault systems, Tectonophysics, 287, 173–186, 1998. a
Norris, R. M. and Webb, R. W.: Geology of California, John Wiley & Sons, Inc., New York, USA, 1990. a
Ogata, Y.: Seismicity analysis through Point-process modeling, Geophys. J. Int., 155, 471–507, 1999. a
Olami, Z., Feder, H. J. S., and Christensen, K.: Self-organized criticality in a continuous, nonconservative cellular automaton modeling earthquakes, Phys. Rev. Lett., 68, 1244–1247, https://doi.org/10.1103/PhysRevLett.68.1244, 1992. a
Omori, F.: On the after-shocks of earthquakes, Journal of the College of Science, Imperial University of Tokyo, 7, 111–120, 1894. a, b
Ozturk, S.: Statistical correlation between b-value and fractal dimension regarding Turkish epicentre distribution, Earth Sci. Res. J., 16, 103–108, 2012. a, b
Peirce, F. T.: Tensile tests for cotton yarns: “the weakest link” theorems on the strength of long and of composite specimens, J. Textile Inst., 17, 355–368, 1926. a
Phoenix, S. L. and Beyerlein, I.: Statistical strength theory for fibrous composite materials, Comprehensive Composite Materials, 1, 559–639, 2000. a
Pradhan, S. and Chakrabarti, B. K.: Failure properties of fiber bundle models, Int. J. Mod. Phys. B, 17, 5565–5581, 2003. a
Pradhan, S., Hansen, A., and Chakrabarti, B. K.: Failure processes in elastic fiber bundles, Rev. Mod. Phys., 82, 499–555, https://doi.org/10.1103/RevModPhys.82.499, 2010. a, b, c
Roy, P. and Ram, A.: A correlation integral approach to the study of 26 January 2001 Bhuj earthquake, Gujarat, India, J. Geodyn., 41, 385–399, 2006. a, b
Sadovskiy, M., Golubeva, T., Pisarenko, V., and Shnirman, M.: Characteristic dimensions of rock and hierarchical properties of seismicity, Izvestiya, Academy of Sciences, USSR, Physics of the Solid Earth, 20, 87–96, 1984. a
Savage, J. and Svarc, J.: Postseismic relaxation following the 1994 Mw6. 7 Northridge earthquake, southern California, J. Geophys. Res.-Sol. Ea., 115, B01401, https://doi.org/10.1029/2010JB007754, 2010. a
Scholz, C.: Spontaneous formation of space-time structures and criticality, edited by: Riste, T. and Sherrington, D., Springer, New York, USA, p. 41, 1991. a
Scholz, C. H.: The mechanics of earthquakes and faulting, Cambridge University Press, UK, 2002. a
Segall, P. and Pollard, D.: Mechanics of discontinuous faults, J. Geophys. Res.-Sol. Ea., 85, 4337–4350, 1980. a
Shi, Y. and Bolt, B. A.: The standard error of the magnitude-frequency b value, B. Seismol. Soc. Am., 72, 1677–1687, 1982. a
Sornette, D.: Elasticity and failure of a set of elements loaded in parallel, J. Phys. A, 22, L243, https://doi.org/10.1088/0305-4470/22/6/010, 1989. a
Stein, R. S.: The role of stress transfer in earthquake occurrence, Nature, 402, 605–609, https://doi.org/10.1038/45144, 1999. a, b
Stein, R. S., King, G. C., and Lin, J.: Stress triggering of the 1994 M= 6.7 Northridge, California, earthquake by its predecessors, Science, 265, 1432–1435, 1994. a, b
Stirling, M. and Goded, T.: Magnitude Scaling Relationships, GNS Science Miscellaneous Series, 42, 1–35, 2012. a
Svalova, V.: Earthquakes: Forecast, Prognosis and Earthquake Resistant Construction, BoD – Books on Demand, https://doi.org/10.5772/intechopen.71298, 2018. a
Thio, H. K. and Kanamori, H.: Source complexity of the 1994 Northridge earthquake and its relation to aftershock mechanisms, B. Seismol. Soc. Am., 86, S84–S92, 1996. a
Turcotte, D. L.: Fractals and chaos in geology and geophysics, Cambridge University Press, UK, 1997. a, b, c, d, e
Turcotte, D. L., Newman, W. I., and Shcherbakov, R.: Micro and macroscopic models of rock fracture, Geophys. J. Int., 152, 718–728, 2003. a
Scientists of the U.S. Geological Survey: The Magnitude 6.7 Northridge, California, Earthquake of 17 January 1994, Science, 266, 389–397, 1994. a
Utsu, T. and Ogata, Y., M. R.: The centenary of the Omori formula for a decay law of aftershock activity, J. Phys. Earth, 43, 1–33, 1995. a, b
Vázquez-Prada, M., Gómez, J., Moreno, Y., and Pacheco, A.: Time to failure of hierarchical load-transfer models of fracture, Phys. Rev. E, 60, 2581–2594, https://doi.org/10.1103/PhysRevE.60.2581, 1999. a
Wallace, R. E.: Active faults, paleoseismology, and earthquake hazards in the western United States, Earthquake Prediction, American Geophysical Union, Maurice Ewing Series 4, Washington, D.C., USA, 209–216, 1981. a
Wesnousky, S. G.: The Gutenberg-Richter or characteristic earthquake distribution, which is it?, B. Seismol. Soc. Am., 84, 1940–1959, 1994. a
Wiemer, S. and Wyss, M.: Minimum magnitude of completeness in earthquake catalogs: Examples from Alaska, the western United States, and Japan, B. Seismol. Soc. Am., 90, 859–869, 2000. a
Yewande, O. E., Moreno, Y., Kun, F., Hidalgo, R. C., and Herrmann, H. J.: Time evolution of damage under variable ranges of load transfer, Phys. Rev. E, 68, 026116, https://doi.org/10.1103/PhysRevE.68.026116, 2003. a
Zuniga, F. R. and Wyss, M.: Most-and least-likely locations of large to great earthquakes along the Pacific coast of Mexico estimated from local recurrence times based on b-values, B. Seismol. Soc. Am., 91, 1717–1728, 2001. a